Previous lesson: Code libraries and lists
Dictionaries and complex data structures - EES 2580
In this lesson we introduce a second complex object: dictionaries. A dictionary is a one-dimensional data structure like a list, but its elements are referenced by name using a key rather than by index number.
We can build more complex objects by nesting one object inside another. Two examples we examine are lists of lists and lists of dictionaries.
The pandas module introduces a useful two-dimensional data structure called a DataFrame. We examine the structure of a DataFrame and how to reference its elements.
Learning objectives At the end of this lesson, the learner will be able to:
- create a dictionary by specifying the items it contains.
- add or change dictionary values.
- remove a dictionary value.
- create a complex Python data structure by creating a list that contains lists or dictionaries as list items.
- describe how a list of lists can be compared to cells of a table.
- create a pandas Series from a Python dictionary.
- reference a value in a pandas Series by its label index or integer position index.
- reference a column in a pandas DataFrame by its label index.
- reference a row in a pandas DataFrame by its label index or integer position index.
- reference a cell in a pandas DataFrame by its row and column label indices.
- load a spreadsheet from a URL into a pandas DataFrame.
- use the
.head()method to view the first few lines of a DataFrame. - preform vectorized operations on columns of a pandas DataFrame.
Links
Lesson Jupyter notebook at GitHub
Dictionaries
Introduction to dictionaries (6m51s)
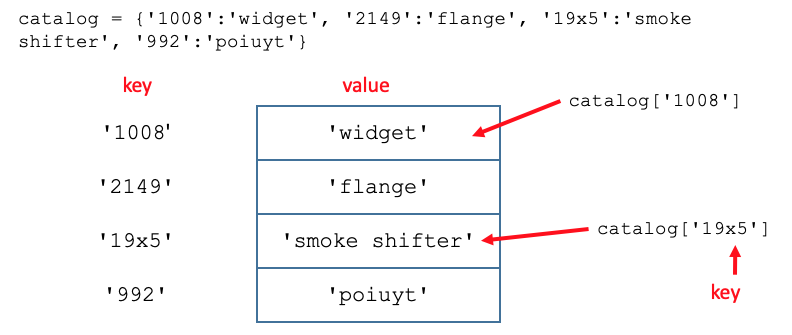
Dictionaries are written as a series of key:value pairs, separated by commas, within curly brackets.
catalog = {'1008':'widget', '2149':'flange', '19x5':'smoke shifter', '992':'poiuyt'}
An empty dictionary can be created using curly brackets with nothing inside them
traits = {}
Both creating and changing a value in the dictionary are done by assigning a value by designated key
traits['height'] = 12
An item can be removed using the del command
del traits['eye color']
Complex data structures
For a more detailed look at this topic that repeats some of this content, go to this page
Lists of lists (5m05s)
A list can contain any object, including other lists. In some programming languages, there are two-dimensional structures called arrays. To create an array-like structure in Python, we can make a list of lists. Here’s an example:
firstRow = [3, 5, 7, 9]
secondRow = [4, 11, -1, 5]
thirdRow = [-99, 0, 45, 0]
data = [firstRow, secondRow, thirdRow]
An equivalent way to have created this list of lists would have been:
data = [[3, 5, 7, 9], [4, 11, -1, 5], [-99, 0, 45, 0]]
We can think of a list of lists like a table where the first index represents the row and the second index represents the column.

To reference an item in a list of lists, first reference the outer list position, then the inner position. For example, to refer to the first item in the third list, use data[2][0]. In the table model, we can think of the indexing as data[column][row].
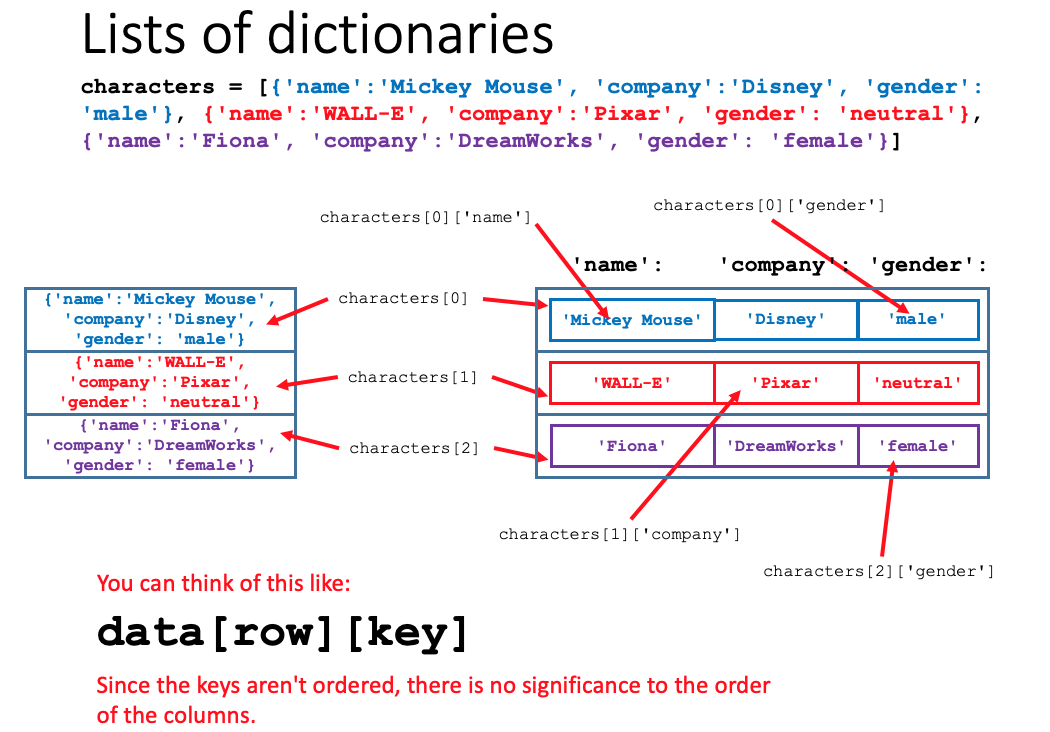
Lists of dictionaries (4m58s)
Example code:
characters = [{'name':'Mickey Mouse', 'company':'Disney', 'gender': 'male'}, {'name':'Daisy Duck', 'company':'Disney', 'gender': 'female'}, {'name':'Daffy Duck', 'company':'Warner Brothers', 'gender': 'male'}, {'name':'Fred Flintstone', 'company':'Hanna Barbera', 'gender': 'male'}, {'name':'WALL-E', 'company':'Pixar', 'gender': 'neutral'}, {'name':'Fiona', 'company':'DreamWorks', 'gender': 'female'}]
Introduction to pandas Series (5m59s)
The form of the statement to create a Series from a Python dictionary is:
series_name = pd.Series(values_dictionary)
pandas Series are similar to both lists and dictionaries since they can be indexed by either a label index (similar to a dictionary key) or an integer position index (similar to the index of a list).
states_series = pd.Series(states_dict)
print(states_series[2])
print(states_series['TN'])
NOTE: As with other Python indexing, the integer position index is zero-based (counting starts with zero). So an integer index of 2 locates the 3rd item in the Series.
To avoid ambiguity, the indexing system can be made explicit by indexing using .loc[] for label indices and .iloc[] for integer position indexing:
states_series.loc['TN']
states_series.iloc[2]
Do not associate the “i” in .iloc[] with the word “index”, since “index” is used generically to describe the label index. It’s better to think of the “i” as representing “integer”.
A pandas Series is composed of a NumPy array with an associated label index object. Basing the Series data structure on a NumPy array allows the Series to be used in vectorized operations and provides better performance than with basic Python data structures like lists and dictionaries.
The .values attribute of a Series returns the NumPy array and the .index attribute returns the label index. Both are iterable.
pandas DataFrame structure (6m28s)
Columns of a data frame can be referred to by their label in two ways:
states_df['capital']
states_df.capital
The “dot notation” can only be used if the column label is a valid Python object name (i.e. can’t have spaces). The resulting object is a series whose values are the values in the column labeled by the row label indices.
Rows in a data frame can be referred to by either their index label (using .loc[]) or their integer position (using .iloc[]):
states_df.loc['AZ']
states_df.iloc[1]
The resulting object is a series whose values are the values in the row labeled by the column headers.
Cells in a data frame can be referred to by their row, column labels (using .loc[]):
states_df.loc['PA', 'population']
The resulting object has the type of the cell value.
Loading a DataFrame from a file
One nice thing about loading spreadsheet data into a pandas DataFrame is that the file can come either from your local file directory or from a URL. The same function can be used for either data source.
Loading a spreadsheet via a URL (3m02s)
Functions for reading and writing from spreadsheets to pandas DataFrames:
pd.read_csv() read from a CSV file into a data frame.
pd.to_csv() write from a data frame to a CSV file.
pd.read_excel() read from an Excel file into a data frame.
pd.to_excel() write from a data frame to an Excel file.
For details about reading from particular sheets in an Excel file, delimiters other than commas, etc. see the pandas User Guide and this Stack Overflow post.
Note: when loading files via a URL, be sure that the URL delivers the raw file, not an HTML representation of the file.
When a CSV file is loaded into a DataFrame, the first row of the file is assumed to contain the column headers. Those column headers are automatically set to be the label indices for the columns. However, no particular column is set as the label indices for the rows. The default row label indices are a sequence of integers starting with zero. To set a column to be the row indices, use the .set_index() method:
dataframe = dataframe.set_index('row_ids')
where row_ids is a column containing unique values that will be used as the row label indices.
Examining the DataFrame
Use the .head() method to view only the first few lines of a DataFrame (default is 5 if number_of_lines argument omitted):
dataframe.head(number_of_lines)
The .tail() method is similar, but shows the last few lines of a DataFrame
The .shape attribute returns a tuple of the number of rows and number of columns.
The .columns attribute returns the column names as a pandas Index object. Use the list() function to convert into a simple Python list.
The .index returns the row label indices as a pandas Index object. Use the list() function to convert into a simple Python list.
Practice assignment
Instructions: The questions for the practice assignment are in this Jupyter notebook at GitHub. Download it to your local drive within the GitHub repository you created for this course.
When you’ve finished the assignment, be sure to save a final time. Do not clear the output so that viewers can see what the output was when you submit the assignment. Commit the changes to the repository and push the changes to the remote repository on GitHub.
Go to the web page for the repository on GitHub and locate the notebook. Submit the link for the notebook web page to Brightspace as instructed.
Next lesson: Loops and contitional execution
Revised 2024-03-06

Questions? Contact us
License: CC BY 4.0.
Credit: "Vanderbilt Libraries Digital Lab - www.library.vanderbilt.edu"