Earth Systems Dynamics (EES 2580) Python Project Rubric and Instructions
- Lesson 1: Background
- Lesson 2: Python programming basics
- Lesson 3: Code libraries and lists
- Lesson 4: Dictionaries and complex data structures
Project Part 1: Data Acquisition and Analysis with Python
Learning objectives:
The learner will:
- acquire data from a tabular data source and load it into a Python data structure (pandas DataFrame).
- extract necessary data from the data structure and wrangle it into a form usable in their analysis.
- use the basic Python statements they have learned:
if,for, assignment, use a function from a module, apply methods to an object. - create simple visualizations of temperature and precipitation over time using
matplotlib.pyplot.
Criteria
1. Data Acquisition (20 points)
- Exemplary (20-18 points): Student successfully acquires data from a tabular data source, loading it into a pandas DataFrame. The process is well-documented and error-handling is implemented effectively.
- Proficient (17-14 points): Student is able to acquire data and load it into a pandas DataFrame, with minor errors in documentation or handling.
- Developing (13-10 points): Student encounters some difficulties in acquiring and loading the data, with notable errors in documentation or handling.
- Needs Improvement (9-0 points): Student struggles significantly with acquiring and loading data, with inadequate documentation or handling of errors.
2. Data Wrangling (30 points)
- Exemplary (30-27 points): Student extracts necessary data from the DataFrame and successfully wrangles it into a usable form for analysis. Data manipulation techniques are effectively applied.
- Proficient (26-21 points): Student extracts most of the necessary data and conducts basic data wrangling, with some inconsistencies or minor errors.
- Developing (20-15 points): Student struggles with extracting necessary data or encounters difficulties in wrangling the data into a usable form.
- Needs Improvement (14-0 points): Student demonstrates limited ability to extract necessary data or perform data wrangling.
3. Python Proficiency (30 points)
- Exemplary (30-27 points): Student demonstrates proficient use of basic Python statements (if, for, assignment), effectively utilizes functions from modules, and applies methods to objects.
- Proficient (26-21 points): Student applies basic Python statements adequately but may demonstrate some inconsistencies or errors.
- Developing (20-15 points): Student struggles with basic Python statements and may have difficulty applying functions or methods correctly.
- Needs Improvement (14-0 points): Student demonstrates limited understanding or application of basic Python statements.
4. Data Visualization (20 points)
- Exemplary (20-18 points): Student creates multiple clear and informative visualizations using matplotlib.pyplot that effectively represent the analyzed data.
- Proficient (17-14 points): Student creates a visualization that represents the data adequately, but may have minor inconsistencies or lack some clarity.
- Developing (13-10 points): Student attempts to create a visualization but encounters difficulties in clarity or effectiveness.
- Needs Improvement (9-0 points): Student demonstrates limited ability to create a visualization or fails to do so.
Total: 100 points
Project Part 2: Data interpretation (20 points)
In addition to submitting your Python notebook, please submit a word document or pdf that addresses the following.
Please write one paragraph that describes in your own words what your plots show. This paragraph should answer the following questions: How do temperature and precipitation evolve over time? What evidence suggests that temperature and precipitation are or are not changing through time?
You can get up to four bonus points for embedding figures you produced via your python script into your word document. To get the bonus points, you must include a caption that describes the figure below each figure.
Project Goals and Requirements
Overall goals
Monthly average climate data in tabular form is available from the National Centers for Environmental Information https://www.ncdc.noaa.gov/cdo-web/ for a number of locations around the U.S. We will be analyzing data for Mesa, Arizona from 1896 through 2017. The data have been extracted and stored in GitHub here. The data look like this:
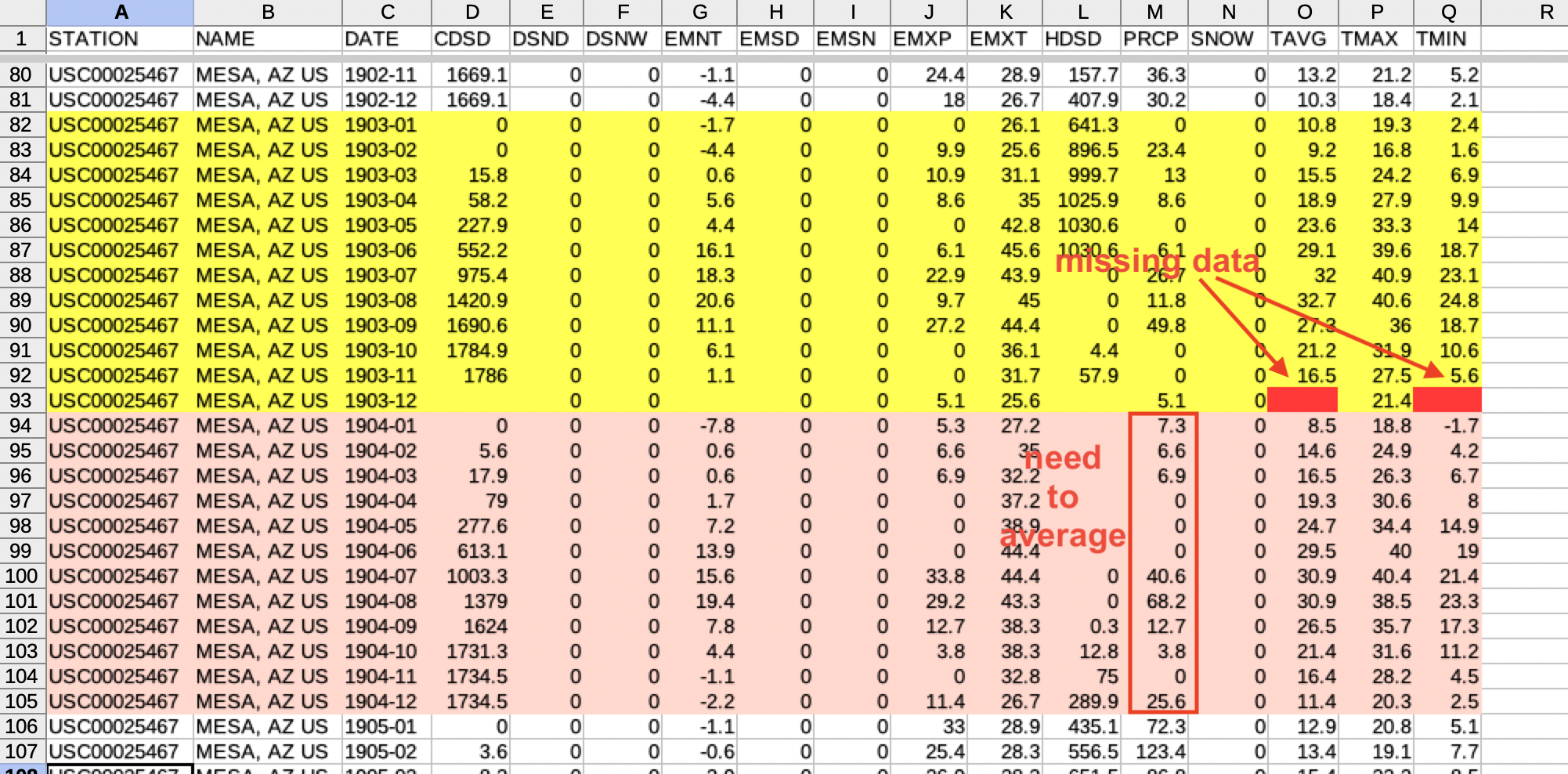
In order to visualize these data, we need to summarize it by averaging values by year or by month. We also will need to deal with situations where values are missing.
In the end, we want one Series containing the time values to be plotted (the X values) and another Series with the average values for the climatic variable that corresponds to those time values (the Y values). We will be creating four plots:
- mean precipitation by year
- mean temperature by year
- mean precipitation by month
- mean temperature by month
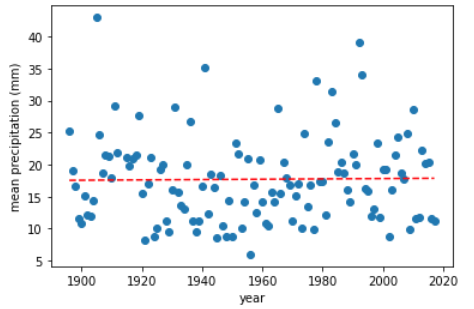
We can then visualize these data using Matplotlib. Here is an example for the data above:
Specific requirements
Each plot must have descriptive axis labels, including units if appropriate. These are the four required plots:
- Create an XY scatter plot of mean precipitation by year. Add a linear trendline (first-order polynomial) fit to the data.
- Create an XY scatter plot of mean temperature by year. Add a linear trendline (first-order polynomial) fit to the data.
- Create a bar plot of mean precipitation by month.
- Create an error bar plot of the mean temperature by month with the error bars representing the mean maximum and mean minimum values for each month.
Much of the data wrangling code can be reused with modification after you complete the first plot.
Tasks and subtasks
1 Acquire data and wrangle the dates
1.1 Use the pd.read_csv() function to load CSV from URL to a pandas DataFrame.
1.2 Split the YYYY-MM date strings into separate year and month columns
1.3 Create a list of intervals for the desired time range
2 Calculate means for desired quantity (rainfall or temperature)
2.1 Create an empty table
2.2 Step through all of the time intervals and calculate the mean
2.2.1 Slice the DataFrame to include only the current time interval
2.2.2 Calculate the mean for the slice
2.2.3 Skip missing data
2.2.4 Add the calculated data to the table
2.3 Turn the table into a pandas DataFrame
3 Visualize data
3.1 Create subplot
3.2 Plot data using appropriate style (scatterplot, bar, error bars)
3.3 Add trendline if appropriate
3.3.1 Fit linear polynomial to summary data
3.3.2 Add polynomial data to plot
3.4 Label axes
Task details
These are the specific steps required to create a plot of mean precipitation by year (the first plot).
You will need to include the following import statements at the beginning of your script:
import requests
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
1 Acquire data.
The URL for loading the CSV of raw data is: https://raw.githubusercontent.com/HeardLibrary/digital-scholarship/master/data/codegraf/mesa2880172.csv
1.1 Use the pd.read_csv() function to load the CSV from URL to a pandas DataFrame
1.2 In order to pull out the mean temperatures for a particular month or year, we need “grouping variable” columns. We can generate these by splitting the date strings in the DATE column into separate year and month columns. If we were using the procedural apprach, we could step through each row and use the .split() method to split the date string into a list of strings. However, it is simpler to use the vectorized approacn and use the .str attribute of the column to apply the .slice() method to the entire column at once. The expression looks like this: climate_data['DATE'].str.slice(0, 4) to get the year, which inludes the first four characters of the string. To assign this expression to a new column in the DataFrame called “YEAR”, we can use this code:
climate_data['YEAR'] = climate_data['DATE'].str.slice(0, 4)
The code for the month is similar. Note that since the date is a string, the slices will also be strings, even though they look like numbers.
1.3 Create a list of years. It would be possible to calculate the mean precipitation for each and generate an output table in a single vectorized expression. However, that involves more complicated pandas than we have learned. Instead, we will use a loop to step through each year and calculate the mean precipition for that year.
In order to do that, we need to create a list of years to loop through. We can use the range() function to generate a list of years from 1896 to 2017 by starting with an empty list, then looping through range(1896, 2018) and appending each year to the list.
2 Calculate the mean rainfall for each year.
The strategy we will use is to create a list of dictionaries to represent a table. Each dictionary will represent a row for a year, with the keys being the column names “year” and “precipitation”. We will then use the pd.DataFrame() function to turn the list of dictionaries into a DataFrame.
2.1 Create an empty list to use to build the table.
2.2 Step through all of the years and calculate the mean precipitation for each year.
Set up a for loop to step through each year in the list of years you created.
2.2.1 Slice the DataFrame to include only the iterated year
We can slice a dataframe based on a condition by imposing a boolean condition on a particular column. For example, to slice the dataframe to include only the rows where the year is 1896, we can use this expression:
climate_data[climate_data['YEAR'] == '1896']
where climate_data['YEAR'] == '1896' is a vectorized boolean condition that is applied to the entire column. The result is a slice of the dataframe that includes only the rows where the condition is true.
We will have to be a little careful here because the year in the YEAR column that we created in step 1.2 is a string, while the list of years we are looping through is a list of integers. We can convert the year to a string in the condition by using the str() function:
climate_data[climate_data['YEAR'] == str(year)]
2.2.2 Calculate the mean for the slice.
We learned in the lesson on pandas DataFrames that the .mean() method could be used to calculate the mean of a column as a vectorized operation. So we can use the .mean() method on the slice of the DataFrame to calculate the mean precipitation for that year.
2.2.3 We are now ready to create the dictionary for the year row. However, we don’t want to add a row to the table if there is no data for that year. We can use an if clause to skip the year if there is no data, which will be indicated if the calculated mean produced a NumPy NaN (Not a Number) value. The test for NaN is np.isnan(), so the if expression will look like this:
if not np.isnan(mean_precip):
2.2.4 Add the calculated data to the table
If the mean precipitation is not NaN, we can create a dictionary with the key year and the year loop value, and the key precipitation and the calculated mean precipitation. We can then append this dictionary to the list of dictionaries.
2.3 Turn the table into a pandas DataFrame
The list of dictionaries can be passed directly into the pd.DataFrame() function to create a DataFrame.
3 Visualize data
The plot setup should be fairly straightforward and be similar to examples we did in class.
3.1.1 Create a subplot
We should only need a single subplot (ax) within each figure.
3.2 Plot the annual precipitation data using a scatterplot
Use the .scatter() method to plot the precipitation data. The first argument (x values) should be the year column from the DataFrame you create and the second argument (y values) should be the precipitation column from the DataFrame.
3.3 Add a linear trendline
A trendline is generally appropriate for scatterplots. A linear trendline (best-fit line) is appropriate if we want to assess whether changes over time increase or decrease over the time interval being visualized.
3.3.1 Fit a linear polynomial to annual mean data
Use the np.polyfit() function to fit a linear polynomial to the data and acquire its coefficients. As in the example from the Matplotlib lesson, the final argument is the order of the polynomial, which is 1 for a linear polynomial.
The coefficients can be passed into the np.poly1d() function to create the actual polynomial function that can be use to generate the predicted values for the trendline.
3.3.2 Add polynomial data to plot
Use the .plot() method to add the trendling to the plot. The first argument is the year and the second argument is the polynomial function applied to the year: p(yearly_precip_data['year']). You should make the trendline a different color from the datapoints to make it stand out.
3.4 Label axes
Each axis should be labeled with both the quantity represented on that axis and the units of that quantity.
Creating the other plots
After you have completed the first plot, you can reuse much of the code to create the other plots. The main differences will be in the particular summary data you are plotting and the type of plot you are using. See the “Specific requirements” section for the details of the other plots.
Note that for the error bar plot, you will need to create four columns in the DataFrame: year, month, lower_deviation, and upper_deviation. The lower and upper deviations will need to be calculated by subtracting the mean minimum temperature from the mean temperature and the mean temperature from the mean maximum temperature, respectively.
Revised: 2024-03-18

Questions? Contact us
License: CC BY 4.0.
Credit: "Vanderbilt Libraries Digital Lab - www.library.vanderbilt.edu"