Linked Data Basics: Graphs, URIs, and Triples
There are several key concepts that underlie Linked Data. Fundamentally, Linked Data is a way of modeling data that differs from the more typical table-based database model. Let’s start by looking at graphs, then comparing how the same dataset can be conceptualized under the two models.
Graphs
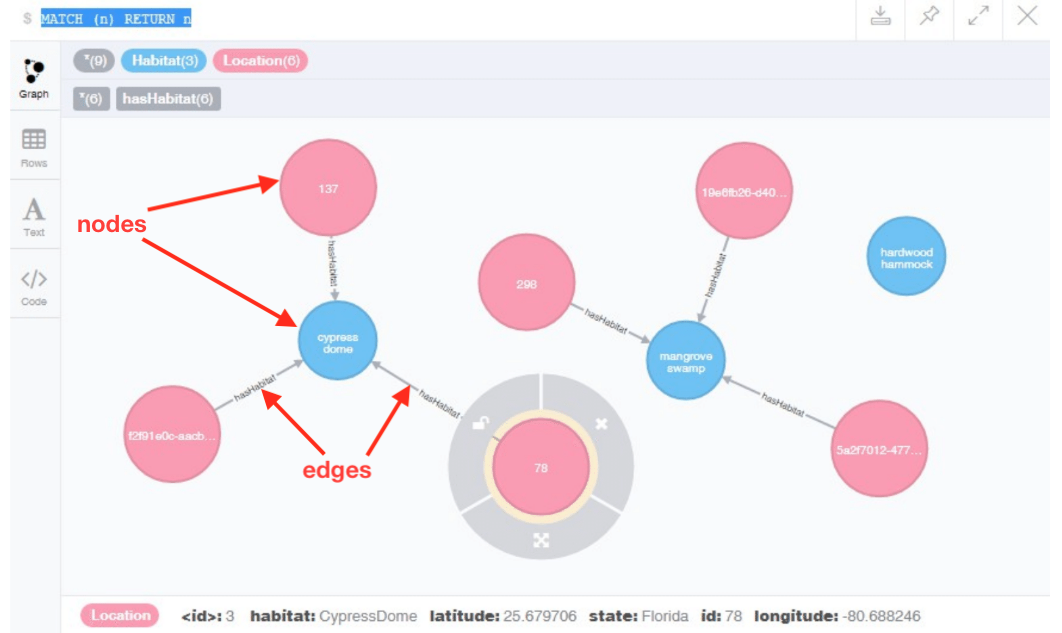
In the context of Linked Data, a graph is an abstract mathematical concept, not a graphical visualization of data as the term is commonly used. A graph is a way of representing how things are connected and is composed of nodes, the entities of interest, and edges, the connections between the nodes. Sometimes a node is also called a vertex (plural vertices) and an edge is sometimes called an arc.
The diagram above shows a graphical representation of a graph. In the graph, the nodes are field sites (shown in pink) and habitat types (shown in blue). The edges (shown as black arrows) represent relationships between the field sites and habitats. This is a “directed graph” because the relationship has a direction indicated by the arrowheads (the field sites have habitat types that are habitats, not the other way around).
Neo4J
Neo4J is a popular graph database system and was used to make the diagram above. Neo4J allows you to designate connections between entities and to record data about the properties of those entities. For example, the field site labeled “78” is in the state of Florida and has the latitude 25.679706 .
Although Neo4J uses a graph model, it isn’t Linked Data because it doesn’t have the basic features of defined for Linked Data
Linked Data
The principles of Linked Data were laid out by Tim Berners-Lee in a 2006 design note.
- Use URIs as names for things
- Use HTTP URIs so that people can look up those names.
- When someone looks up a URI, provide useful information.
- Include links to other URIs. so that they can discover more things.
The primary difference between the approach taken by Neo4J and Linked Data as laid out by Tim Berners-Lee is the use of uniform resource identifiers (URIs) as a means to “name” or identify things. This is a critical difference, because URIs are what makes it possible to link resources described by one data provider with resources described by another. URIs are designed to be globally unique, so when we use them, we know that we won’t have a “collision” when someone else uses the same identifier to refer to a different thing than we are referring to. Neo4J handles graph-based data from a single provider well, but it does not allow for the automatic merging of multiple datasets from different providers - a primary goal of the Linked Data movement.
An 2010 add-on to Linked Data is the idea of Linked Open Data (LOD). LOD is Linked Data that is available under an open license. Today when most people think of Linked Data, they are assuming that it’s open data, so we’ll loosly consider Linked Data and LOD to be the same thing.
URIs
By design, URIs are intended to be globally unique identifiers. A URI is at its heart an identifier, but it may or may not actually be usable for retrieving information on the Internet. URLs (Universal Resource Locators) are a subset of URIs that can be used to retrieve information in a web browser; for example:
https://tools.ietf.org/html/rfc3986
but there are other forms of valid URIs that won’t do anything when typed into a browser, such as:
mailto:steve.baskauf@vanderbilt.edu
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
HTTP URIs
A specific variant of URIs that are of primary interest to Linked Data are HTTP URIs. These are URIs that begin with “http://” or “https://”. The reason these URIs are important to Linked Data is because it’s possible for them to be URLs (i.e. to use them to look stuff up through the Internet). However, just because it’s possible to use an HTTP URI to look something up doesn’t necessarily mean that every valid HTTP URI will actually do something if you paste it into a browser. For example, the HTTP URI
http://ns.adobe.com/xap/1.0/rights/UsageTerms
is a well-kmowm and valid HTTP URI from the International Press and Telecommunications Council Photo Metadata Standard, Extension Schema 1.1, but it does not do anything when you try to look it up on the web. That underscores the point that URIs are always identifiers for things, but they may or may not be usable to retrieve information, even though providing that information is a best-practice in the Linked Data world.
Internationalized Resource identifiers
Internationalized Resource Identifiers (IRIs) are a superset of URIs. The primary difference is that IRIs can contain more characters than the more restricted character set allowed in URIs. For example,
https://en.wiktionary.org/wiki/Ῥόδος
is a valid IRI, but is not a valid URI since it uses letters from the Greek character set.
It is increasingly common to see references to IRIs in the literature, so just be aware that for most purposes, they can be considered somewhat synonymous with URIs.
Compact URIs (CURIEs)
Because URIs are often long and ugly, it has been a longstanding practice to abbreviate them using “namespaces”. Namespaces are a feature of qualified names (or “QNames”) in XML. QNames substitute an abbreviation for the first part of a URI in order to shorten it. For example, if we use ex: as an abbreviation for http://example.org/, then the URI
http://example.org/myData
can be written as the QName
ex:myData
In XML lingo, the abbreviated part http://example.org/ is known as the “namespace”, and the abbrevation ex: may be referred to as the namespace abbreviation. The last part of the URI, myData is often referred to as the “local name”. So a QName is composed of a namespace abbreviation combined with a local name.
Because of their use in XML, QNames have rules that are more restrictive than what we’d like in the context of Linked Data. So a a broader syntax called Compact URIs (CURIEs) was developed. They are essentially QNames, but with fewer restrictions about what constitutes a valid abbreviation. For example, if we consider orcid: to be an abbreviation for https://orcid.org/, we could abbreviate the URI
https://orcid.org/0000-0003-4365-3135
as orcid:0000-0003-4365-3135. This isn’t a valid QName, since the rules of XML require that local names do not begin with numerals. However, it is a valid CURIE, since the rules about local names are more relaxed in CURIEs than in QNames.
You should consider that abbreviated URIs (i.e. CURIEs) are interchangeable with their unabbreviated forms. Thus whenever you see an identifier with a colon in the middle, you should recognize that it stands for a URI. For example,
dcterms:title
is an abbreviation for
http://purl.org/dc/terms/title
with dcterms: as a namespace abbrevation for http://purl.org/dc/terms/ and title as the local name.
Commonly used namespace abbreviations
There are no official rules about what abbreviations should be used for namespaces. However, there are longstanding consensus abbreviations for URIs from many well-known vocabularies and databases. Here are some of the most common ones:
| abbreviation | namespace |
|---|---|
| rdf: | http://www.w3.org/1999/02/22-rdf-syntax-ns# |
| rdfs: | http://www.w3.org/2000/01/rdf-schema# |
| xsd: | http://www.w3.org/2001/XMLSchema# |
| dc: | http://purl.org/dc/elements/1.1/ |
| dcterms: | http://purl.org/dc/terms/ |
| foaf: | http://xmlns.com/foaf/0.1/ |
| skos: | http://www.w3.org/2004/02/skos/core# |
The abbreviations for the two Dublin Core namespaces, dc: and dcterms: are the traditional abbreviations. More recently, other abbreviations have been used, such as dct: instead of dcterms: and using dc: for http://purl.org/dc/terms/ instead of http://purl.org/dc/terms/. For that reason, it’s a best practice to state the abbreviations that you are going to use before you use them.
Building a graph
Conventional tables about people, publications, and institutions
In this example, we will look at a dataset about researchers at Vanderbilt University. The dataset consists of three tables: one about people who do research at Vanderbilt, one about publications written by those researchers, and another about academic institutions (of which Vanderbilt is an instance).
Here are what the tables look like:



The hyperlink above each table will take you to the actual file in our sample data repository.
There are several important columns in each table. Each table has a column containing a unique URI identifier for the item described in each row. In the people table, it’s the orcidId column, in the documents table, it’s the doi column, and in the institutions table, it’s the grid column. In conventional relational database terms, these columns serve as the primary key for the item in the row.
The people table also has an important column: creator. The creator column is the link between the document and the person who created it. In relational database terms, it’s a foreign key that links to the primary key of the person table. Notice that there isn’t any column that links the person table to the institution table. However, since every person in the table is affiliated with Vanderbilt, we can imagine a column in the people table containing the grid ID for Vanderbilt that would link the person to the correct row (the only row!) in the institution table.
In addition to the columns that link one table to another, there are also a number of columns that contain additional metadata about the item, such as starting and ending page numbers for the documents, given names for the people, and the city in which the institution is located. We can consider these columns to describe properties of the entities described in the rows.
There are several columns in the institution table that have HTTP URIs, but that don’t link to any table in this database. For example, there is a URI for Vanderbilt’s website. You could imagine that the database contained a fourth table about websites. In that case, the homepage column in the institutions table could be a foreign key to that website table, which might contain information about web traffic, size of the page, etc.
We can use the following terminology in talking about this database. Each table represents a class of thing (person, document, institution). Each row in a table represents a particular instance of that class (a particular document, a particular person, etc.). Each column header in the table represents a property that exists for the class of that table, and each cell in the table represents the value of the property for the particular instance.
Graph model
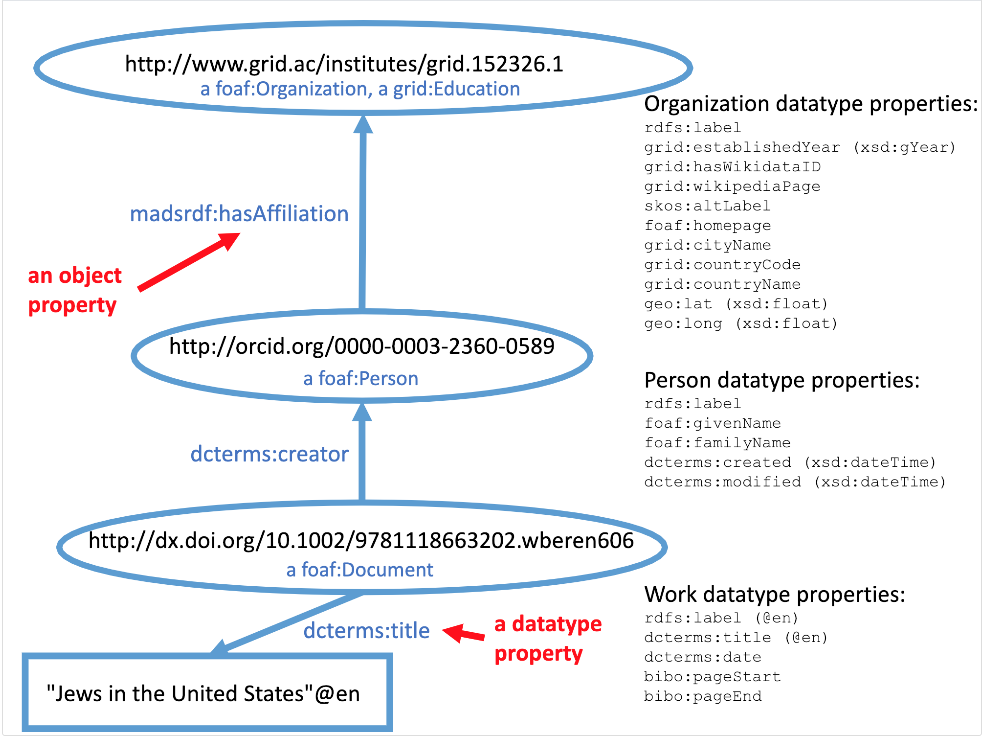
The diagram above shows how the three classes of things are related to each other. (For a larger view of the model, view this PDF). Although each bubble representing a class in the model is labeled with the URI of a particular instance, the bubble represents the class in general.
In this model, we have done a significant thing: we have listed well-known URIs that stand for the kinds of things (the type of the class), the linking properties that connect the classes, and the metadata properties for each column in the tables. For example, foaf:Person or http://xmlns.com/foaf/0.1/Person is a URI from the FOAF vocabulary that we can use to describe the class of persons. dcterms:creator or http://purl.org/dc/terms/creator is a URI from Dublin Core that we can use as a property connecting a document to its creator. dcterms:title or http://purl.org/dc/terms/title is a URI from Dublin core that we can use as a property describing the title of a document.
Notice that it is conventional for the local names of URIs for class types to begin with capital letters (“Person” in foaf:Person) and for the local names of URIs used for properties to begin with lower case letters (“creator” in dcterms:creator). Properties that are used to connect one thing to another thing are sometimes called object properties, and properties that are used to connect a thing to textual (string) metadata about that thing are sometimes called datatype properties.
In “bubble diagrams” it is also conventional to represent entities as ovals, and text metadata as rectangles. So the title of the document shown in this diagram isn’t really a part of the main model, it’s just an illustration of how a datatype property (dcterms:title) connects to text metadata (“Jews in the United States”).
Graph diagram of the dataset

The diagram above shows how the entire dataset present in the three tables can be represented as a graph. (To see a larger version of the graph, click here.) There is one instance of an institution (Vanderbilt University), two instances of people (Julian Hillyer and Shaul Kelner), and five instances of documents (“Jews in the United States”, “Insect immunology and hematopoiesis”, “Let My People Go”, etc.), each represented by an oval. The many text metadata properties of the entities are shown as rectangles. The arrows represent the object and datatype properties that connect the entities to other entities or metadata.
Each arrow connecting one thing to another can be considered a link. We can describe that link by a sort of sentence that describes the connection. For example, we could say:
"Ethnographers and History" creator "Shaul Kelner".
which would describe the connection between two bubbles. But in Linked Data, we use URIs to name things, so using the URIs for the two entities, we could say:
<http://dx.doi.org/10.1353/ajh.2014.0012> dcterm:creator <http://orcid.org/0000-0003-2360-0589>.
Notice that in writing this kind of sentence, unabbreviated URIs are enclosed in angle brackets, while CURIEs (abbreviated URIs) are written by themselves. This kind of statement is called an RDF triple. Resource Description Framework (RDF) is the W3C Standard for describing graphs in Linked Data. (A resource is any kind of thing - it’s what we have been referring to as “entities” elsewhere on this page.) In an manner analogous to a sentence, the first part of the triple is called the subject, the second is the precicate (synonymous with property), and the third is the object. The triple is ended with a period.
The graph as RDF triples
We can describe the graph completely by simply writing a triple for every connection in the graph diagram. That has been done in this table. There are 66 triples in the graph. If you count the arrows in the diagram, you will find fewer than 66 because the label properties are written under the bubbles rather than showing them linked as arrows.
Since the Wikipedia page, Vanderbilt website, and Wikidata entry for Vanderbilt (Q29052) are identified with URIs, they are shown as bubbles rather than rectangles in the bubble chart, and are enclosed in angle brackets in the table of triples. If we were able to retrieve additional things about those three URI-identified resources (which we could do for at least the Wikidata entry), we could extend the graph as Tim Berners-Lee suggested in his fourth characteristic of Linked Data.
Some final notes
If you examine the table of triples carefully, you will notice several things:
- Subjects and predicates of triples are always URIs. Objects can be either URIs or literals (text strings).
- Some of the literals are followed by a datatype, e.g.
"2014-12-22T22:25:56.900Z"^^xsd:dateTime. This provides additional information about how to interpret the string, and indicates that it is actually an abstract resource (an instant of time) rather than just text. - Some of the literals are followed by a language tag, e.g.
"Insect immunology and hematopoiesis"@en. Sometimes a property will be repeated with several values in different languages. - The predicate
rdf:typeis a really important property that is used to indicate the class to which the resource belongs. It is a best practice to indicate the type of every resource if possible. - The predicate
rdfs:labelis an important property that helps consuming applications to know how to label entities. That’s how the software that built the bubble diagram knew what labels to put under the bubbles. - There is no problem with repeating properties, or with declaring an resource to be a member of more than one class (i.e. to give it more than one rdf:type property). For example, Vanderbilt University was declared to be both a
foaf:Organizationand agrid:Education.
For more information
If you want to watch a quirky video on this topic, view this YouTube video
next lesson on serializations and triplestores
Revised 2019-01-14

Questions? Contact us
License: CC BY 4.0.
Credit: "Vanderbilt Libraries Digital Lab - www.library.vanderbilt.edu"