previous lesson on graphs, URIs, and triples
Linked Data Basics: RDF Serializations and Triplestores
Since RDF is an abstract model for expressing information about graphs, it can be expressed in a number of concrete ways. One way that is particularly easy for humans to understand is a graphical diagram. The triples in this table form a graph that can be represented by this diagram:

However, it is generally not possible for machines to interpret graphs that are expressed as diagrams. Machine need an RDF serialization, a method of transmitting or storing the information about the triples in the graph as a file.
N-Triples
The simplest RDF serialization is called N-Triples. In N-Triples, the URIs that are included in the triple are written in their unabbreviated form and enclosed in angle brackets. String literals are enclosed in double quotes and can be followed by either a language tag or datatype URI (written in unabbreviated form).
The subject, predicate, and object are written in order. The end of the triple is indicated with a period, followed by a newline character (hard return) - in other words, each triple is written on a separate line.
Here is an example of part of the graph diagrammed above:
<http://orcid.org/0000-0002-3178-0201> <http://purl.org/dc/terms/created> "2014-12-22T22:25:56.900Z"^^<http://www.w3.org/2001/XMLSchema#dateTime>.
<http://orcid.org/0000-0002-3178-0201> <http://www.loc.gov/mads/rdf/v1#hasAffiliation> <http://www.grid.ac/institutes/grid.152326.1>.
<http://orcid.org/0000-0002-3178-0201> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person>.
<http://orcid.org/0000-0002-3178-0201> <http://www.w3.org/2000/01/rdf-schema#label> "Julian Hillyer".
(Scroll the code window to the right to see all of the triples.) Download file
N-Triples is not particularly easy to read because no abbreviation of URIs is allowed. But it is very easy to write software to consume it, and it’s easy to manipulate the triples in a file, since each triple is on a separate line.
RDF text files in N-Triples serialization are usually given the file extension .nt.
Turtle
Turtle stands for “Terse RDF Triple Language”. N-Triples is a subset of the RDF Turtle serialization, meaning that any file that is valid N-Triples is also valid Turtle serialization. However, Turtle allows compact URIs (CURIEs) and also allows shortcuts to prevent repeating parts of triples. For example, if several triples share the same subject, the predicates and objects can be listed, separated by semicolons. Here are the same triples as in the previous example, serialized as Turtle:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix orcid: <http://orcid.org/> .
@prefix mads: <http://www.loc.gov/mads/rdf/v1#> .
orcid:0000-0002-3178-0201 dcterms:created "2014-12-22T22:25:56.900Z"^^xsd:dateTime;
mads:hasAffiliation <http://www.grid.ac/institutes/grid.152326.1>;
rdf:type foaf:Person;
rdfs:label "Julian Hillyer".
The namespace prefixes that are used in the triples must be listed in a prolog at the start of the document. Notice that URIs aren’t required to be abbreviated.
In Turtle, you can use whitespace to make the triples more readable. In this example, the second through fourth triples are indented to show that they share the same subject.
If two triples share both the same subject and predicate, the two objects can be separated by commas. For example:
orcid:0000-0002-3178-0201 rdf:type foaf:Person;
rdfs:label "Julian Hillyer",
"J. Hillyer".
Turtle also allows a special abbrevation for the important predicate rdf:type. It can be replaced with a. For example:
orcid:0000-0002-3178-0201 a foaf:Person.
RDF text files in Turtle serialization are usually given the file extension .ttl.
XML
XML is the oldest serialization of RDF. For that reason, it is still one of the most commonly provided forms of RDF. Many people who are unfamiliar with XML find it difficult to read and interpret as triples. However, one advantage is that it can be generated from other forms of data using tools like XQuery. We won’t be discussing the structure of RDF/XML here, but here is what the four triples shown in our previous example look like when serialized as XML:
<?xml version="1.0" encoding="utf-8" ?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:mads="http://www.loc.gov/mads/rdf/v1#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<foaf:Person rdf:about="http://orcid.org/0000-0002-3178-0201">
<dcterms:created rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">2014-12-22T22:25:56.900Z</dcterms:created>
<mads:hasAffiliation rdf:resource="http://www.grid.ac/institutes/grid.152326.1"/>
<rdfs:label>Julian Hillyer</rdfs:label>
</foaf:Person>
</rdf:RDF>
RDF text files in XML serialization are usually given the file extension .rdf.
JSON-LD
One of the newest RDF serializations is JSON-LD. It is gaining popularity because of the widespread use of JSON in APIs and as a broadly usable data trasfer format. JSON-LD is now a preferred format for providing structured data to the Google knowledge graph in web pages.
JSON-LD is actually a broader serialization for Linked Data since it includes additional features that are not included in strict RDF. However, valid RDF can be transformed into JSON-LD. There are actually several equivalent forms of JSON-LD (expanded, compacted, flattened, and framed) - see the JSON-LD Playground for more details.
Here’s the four triples we’ve been looking at (in compacted form):
{
"@id": "http://orcid.org/0000-0002-3178-0201",
"@type": "http://xmlns.com/foaf/0.1/Person",
"http://purl.org/dc/terms/created": {
"@type": "http://www.w3.org/2001/XMLSchema#dateTime",
"@value": "2014-12-22T22:25:56.900Z"
},
"http://www.loc.gov/mads/rdf/v1#hasAffiliation": {
"@id": "http://www.grid.ac/institutes/grid.152326.1"
},
"http://www.w3.org/2000/01/rdf-schema#label": "Julian Hillyer"
}
As in the case of XML, JSON-LD is intended primarily for machine consumption, so we won’t belabor its details. If you are interested in more information about JSON, JSON-LD, and providing structured data in web pages, see this presentation.
JSON-LD files are usually given the default JSON file extension .json.
Validating and converting between serializations
There are several online tools that can be used to validate and convert small RDF files from one serialization to another. The best one is probably RDF Translator, but the EasyRDF Converter also works pretty well.
Large files can be validated and converted using the rdfEditor application, part of the dotNetRDF package of programs. Unfortunately, it is only available for Windows.
The W3C provides an RDF validator that unfortunately only accepts RDF/XML input. However, it is one of the few online services that will provide a graphical diagram of the graph. Select the “Graph only” option of “Triples and/or Graph” before parsing the RDF. Here’s an example of the output from the RDF/XML example above.

By using one of the converter tools to convert an RDF serialization to XML, then the W3C Validator, it’s possible to generate a diagram for any serialization.
Designating and identifying graphs
Although triples can be serialized in a text document in one of the formats described above, simply existing in the same document does not make particular triples be part of a particular graph. One of the features of RDF is that when triples are placed together in the same graph, they lose any identity that they may have had due to their source or theri position in a particular document. That is good, because it makes it extremely easy to merge datasets from different sources. However, it can also be bad because once the triples are dumped into a triplestore, we can lose track of any information about their provenance.
Graph URIs and N-Quads
The solution to this is to associate triples with a graph URI. A URI can be used to uniquely identify anything, including sets of triples (which is essentially a way to define a graoph). Because there is no requirement that a URI actually resolve to anything, or be used to retrieve something (as in the case of a URL), we can simply “make up” a URI to refer to a set of triples. As long as the form of the URI is valid, we can use any URI that we like. (If we are concerned about possible collisions of a graph URI that we mint with graph URIs created by someone else, we should use a domain name that we control and have a systematic method for generating the URIs.)
Let’s say that we want to identify the set of four triples that we’ve been using in our examples using the URI http://library.vanderbilt.edu/ldwg/researchers. There is a variant of N-Triples called N-Quads that allows us to designate that a particular triple is part of a particular graph. The rules for N-Quads are essentially the same as for N-Triples, except that a fourth URI is added to each line indicating the graph to which the triple belongs. Here is what our sample data would look like in N-Quads serialization if we assign the triples to the http://library.vanderbilt.edu/ldwg/researchers graph:
<http://orcid.org/0000-0002-3178-0201> <http://purl.org/dc/terms/created> "2014-12-22T22:25:56.900Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> <http://library.vanderbilt.edu/ldwg/researchers>.
<http://orcid.org/0000-0002-3178-0201> <http://www.loc.gov/mads/rdf/v1#hasAffiliation> <http://www.grid.ac/institutes/grid.152326.1> <http://library.vanderbilt.edu/ldwg/researchers>.
<http://orcid.org/0000-0002-3178-0201> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> <http://library.vanderbilt.edu/ldwg/researchers>.
<http://orcid.org/0000-0002-3178-0201> <http://www.w3.org/2000/01/rdf-schema#label> "Julian Hillyer" <http://library.vanderbilt.edu/ldwg/researchers>.
(Scroll the code window to the right to see all of the quads.) Download file
The recommended file extension for N-Quads is .nq.
RDF datasets and the default graph
An RDF dataset refers to a collection of graphs that interest us for some purpose. In an RDF dataset, all but one of the graphs are named graphs. The unnamed graph is called the default graph.
If we refer to a set of triples without designating that it is associated with a named graph, we can assume that those triples are part of the default graph. For example, if an application expects an N-Quad file but we provide it with an N-Triple file (essentially an N-Quad file with the graph URIs missing), the application will assume that the triples belong to the default graph.
There is some lack of clarity about the exact meaning of RDF datasets and the roles of default and named graphs within them, and there are inconsistencies in how different applications handle cases where the name of a graph isn’t specified. For more details, see the W3C RDF Datasets document and this blog post. For those wha aren’t interested in the details, we can say that there are two “safe” approaches:
- don’t care about dividing triples up among named graphs and dump all triples that we want to consider part of our dataset into the default graph
- care about dividing triples among named graphs and make sure that every triple is part of a named graph
The troublesome situations occur when we mix triples from named graphs with triples where no graph is specified.
An aside on meaning
Although in its simplest form, an RDF graph is an abstraction involving URIs and strings, the reason we are interested in creating graphs is because they are a mechanism for encoding knowledge. That’s why we use the term knowledge graph to indicate that the graph of Linked Data mean something.
There are several ways that we indicate meaning in RDF graphs. One is through datatyping of literals. For example, take the following triple as an example:
<http://orcid.org/0000-0002-3178-0201> dcterms:created "2014-12-22T22:25:56.900Z"^^xsd:dateTime .
By adding the datatype xsd:dateTime we are indicating that “2014-12-22T22:25:56.900Z” is not just a random string of characters, but that it denotes a real thing: an instant of time. The datatype indicates that the format of the string conforms to a system for representing that real thing.
The other way we encode meaning is by using a standarized vocabulary to define the URIs that we use for predicates, and the class URIs that we use as objects for rdf:type. For example, dcterms:created means the “date of creation of the resource”. Using this vocabulary makes it clear what dcterms:created means.
However, just using that term does not make the triple represent reality. The subject resource is the person named Julian Hillyer. From the triple, we might infer that Julian Hillyer was born on Dec. 22, 2014. But that is clearly not true, since he published a paper and must be more than 5 years old in 2019. The triple actually refers to the date of the creation of the ORCID record about Julian Hillyer, which is a different thing.
Thus we can see that simply making an assertion in RDF does not make that statement true, even if we have valid RDF using standardized terms.
Loading data into a triplestore
There are very few useful things we can do with linked RDF data unless we can load it into a triplestore. There are three main ways that we can load data:
- Using a graphical interface (GUI)
- Using HTTP POST
- Using software intermediaries
We will see how to load data in all three of these ways in the sections that follow.
Loading data using a GUI
The Metaphactory triplestore has a graphical interface that allows users to load files by drag and drop:
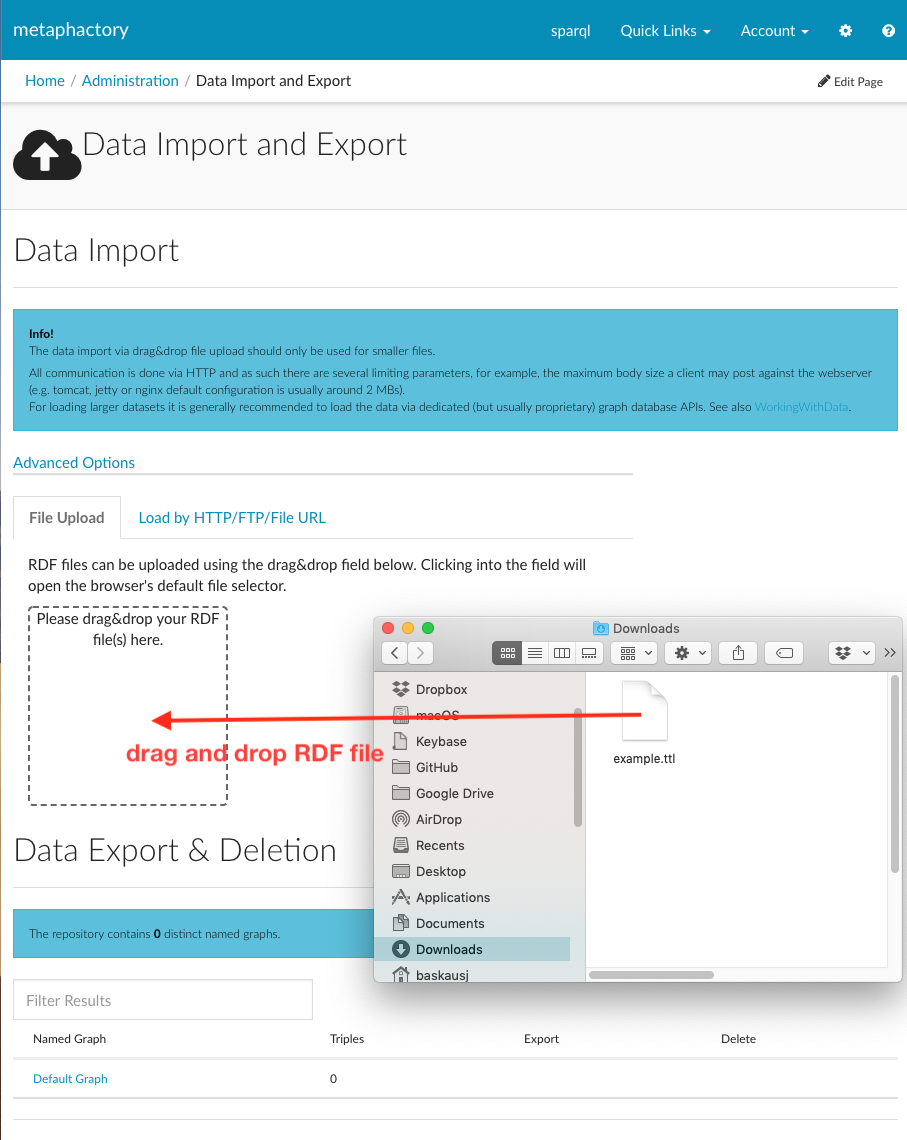
After the file loads, the interface reports that 4 triples were loaded. By default, Metaphactory assigns all triples contained in a file loaded by drag-and-drop to a graph whose name is created from the file name and the load time:
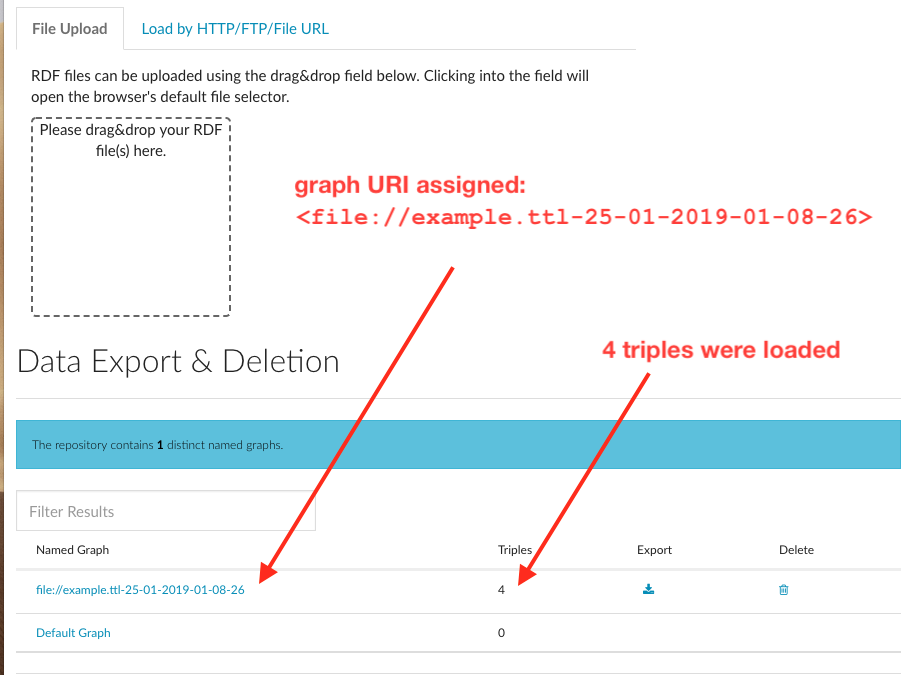
We can examine the contents of the graph by running a SPARQL query using the query interface and this query:
SELECT *
FROM <file://example.ttl-25-01-2019-01-08-26>
WHERE {
?sub ?pred ?obj .
}
Don’t worry about the format of the query - it just lists every triple present in the graph. When we run the query, we see in the output the same four triples as in the input document.
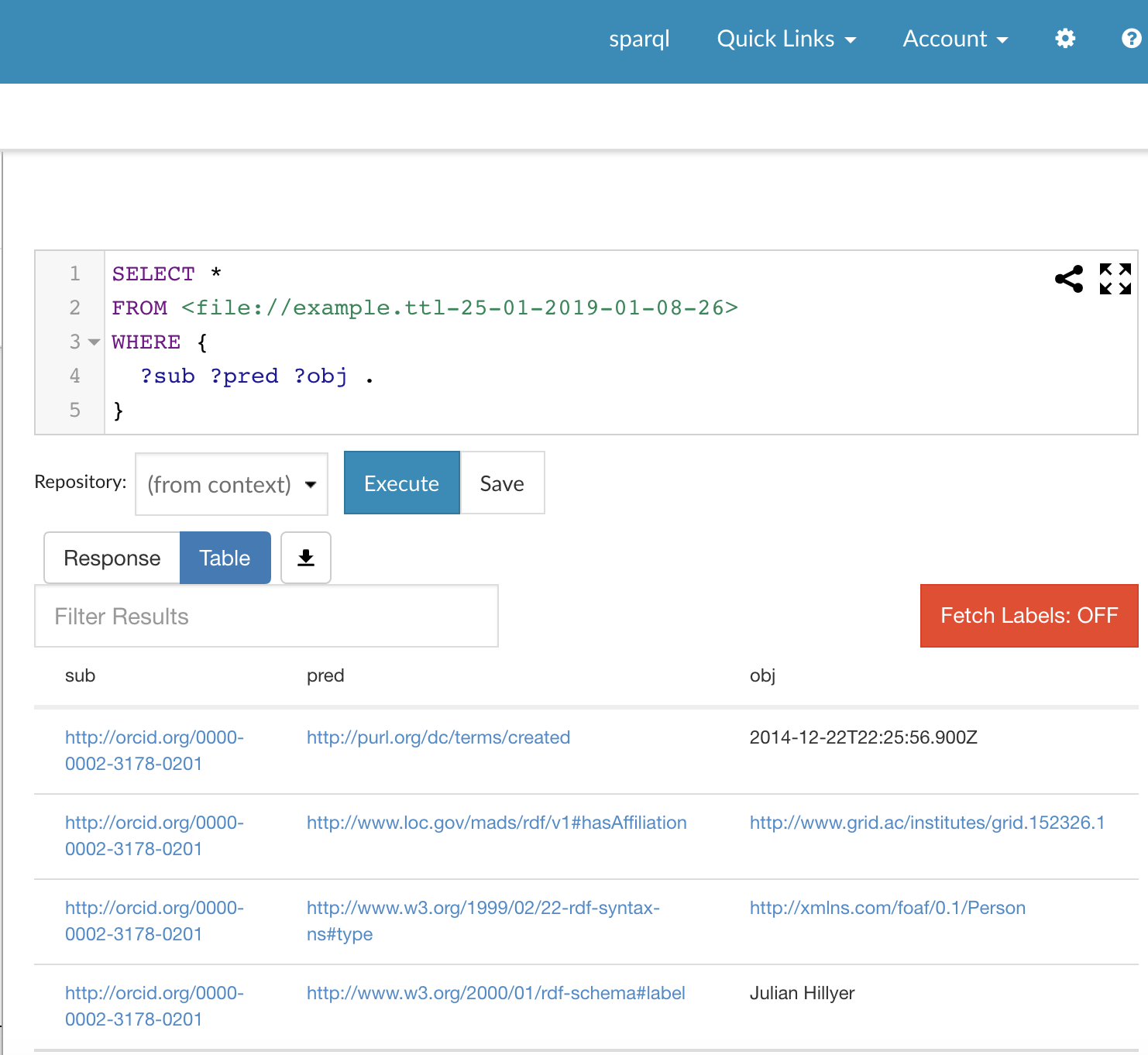
One problem with this GUI loading method is that it is not possible to specify a graph URI of our choice.
An aside on HTTP
To understand how we can interact with a triplestore (a graph database that stores RDF triples), we need to know a little bit about HyperText Transfer Protocol (HTTP) and its cousin, HTTPS (secure HTTP).
Most people have seen the http:// that is the start of most URLs. Today, many URLs start with https:// indicating that communication is secure. Regardless of the flavor, the HTTP protocol specifies how software on a local computer (the client) interacts with a remote computer (the server).
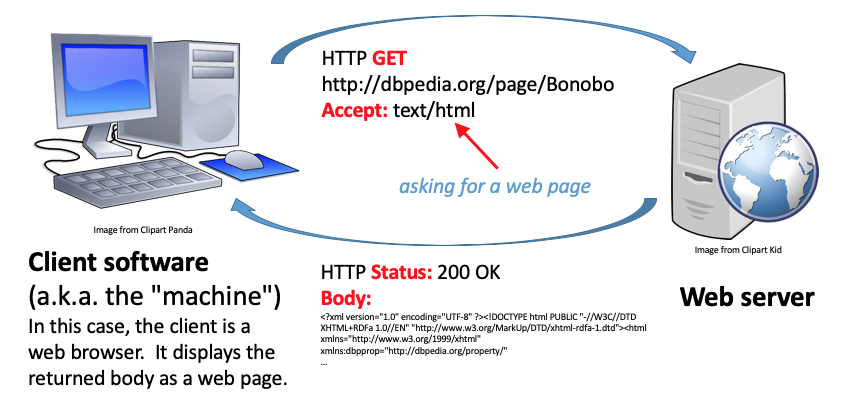
There are several kinds of transactions that can take place via HTTP. The diagram above illustrates one of the most common, a GET request. In a GET request, the client asks the server for a document. In the example above, the client is a web browser, and the document requested is an HTML web page. There are several key parts to the GET transaction:
- the URL identifies the server
- an Accept header says what kind of document the client wants (in this case text/html; a web page)
- an HTTP status code (indicating if the server was successful in finding and serving; 200 “Success” in this case)
- the response body containing the content of the file (in this case the HTML text document)
If you carry out this transaction in a web browser, all of this interaction takes place under the hood. When the browser receives the HTML text document, it renders it as a web page suitable for a human viewer.
If you want to actually see the gory details of the transaction, you can use client software that will show you what’s going on in the interaction. We can use Postman to see what’s actually going on:
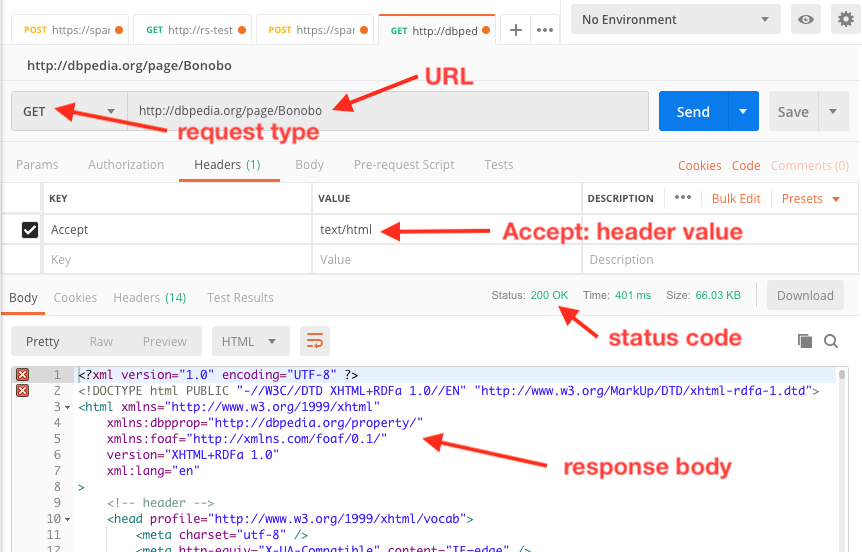
We can interact with a triplestore using HTTP GET if we want to query it. We can also use another kind of HTTP request, POST, to load data into the triplestore.
Loading data using SPARQL UPDATE
The W3C SPARQL Protocol and RDF Query Language (SPARQL) has an update language component that makes it possible to load data into a triplestore using HTTP. The LOAD command allows all of the data in a document to be loaded into a specified named graph. This is significant because it allows us to choose the graph into which the triples are added. If we wanted, we could insert triples from several documents into the same graph, rather than having a separated graph for each document as was the case in the previous example where the graph name was assigned based on the document name.
The format of the SPARQL Update LOAD command is
LOAD <source URL> INTO GRAPH <graph URI>
The graph URI is the URI of the graph into which the triples should be inserted. source URL is the location from which the source document can be retrieved. The source URL can be a file location on the local computer if the file: URI type is used. It can also be retrieved from a location on the Internet if an http: or https: URI is used.
One possible issue with using the LOAD command is that it does not contain any mechanism for indicating the serialization of the RDF in the source file. Depending on the endpoint to which the LOAD command is sent, the endpoint may require that the server designate the serialization type through a Content-Type: header during the HTTP response. If an appropriate response header is not generated by the server, the endpoint may fail to load the file.
This is a problem with serving raw files from GitHub, since raw files are always served with a header of text/plain, which is not an Internet Media Type (MIME type) for any RDF serialization. The appropriate media types for the serializations discussed above are shown in the following table:
| RDF serialization | media type |
|---|---|
| XML | application/rdf+xml |
| Turtle | text/turtle |
| N-Triples | application/n-triples |
| N-Quads | application/n-quads |
| JSON-LD | application/ld+json |
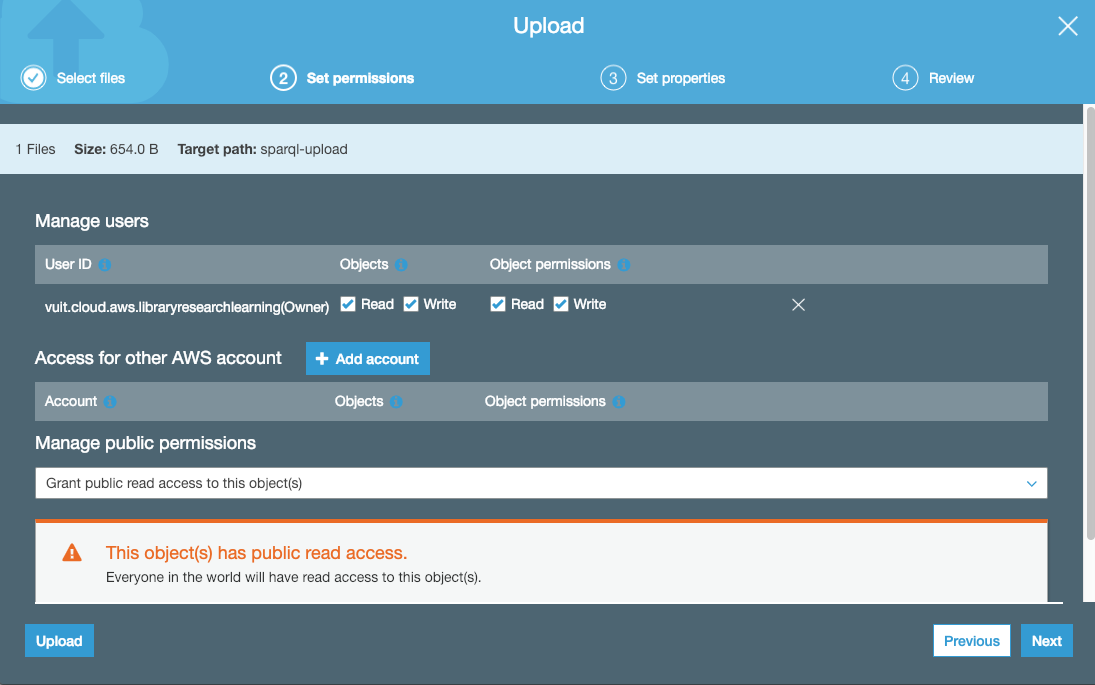
One mechanism for serving a file with an appropriate Content-Type: header is to put the file in an AWS S3 bucket. The bucket has to be publicly accessible, and when the file is loaded, it also has to be set to grant public access to the file itself:
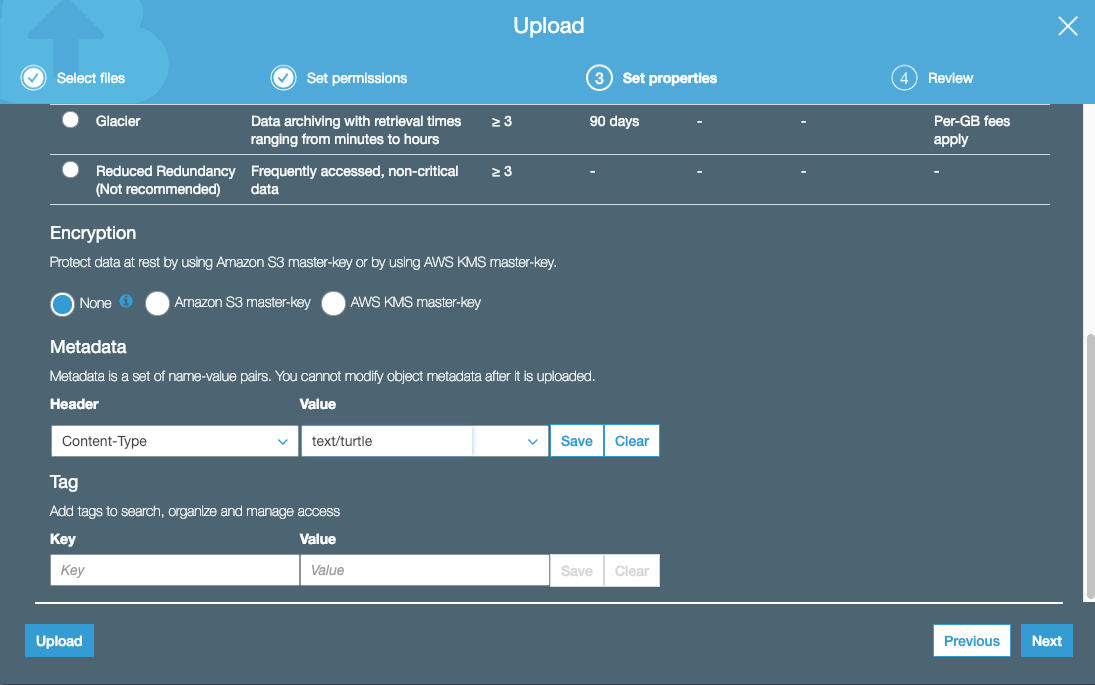
In the Set Properties dialog, set a Content-Type header appropriate for the serialization type of the file:
After the file is uploaded, click on the file name to observe it’s properties. Copy the Object URL to use as the LOAD URL in the SPARQL Updated command.
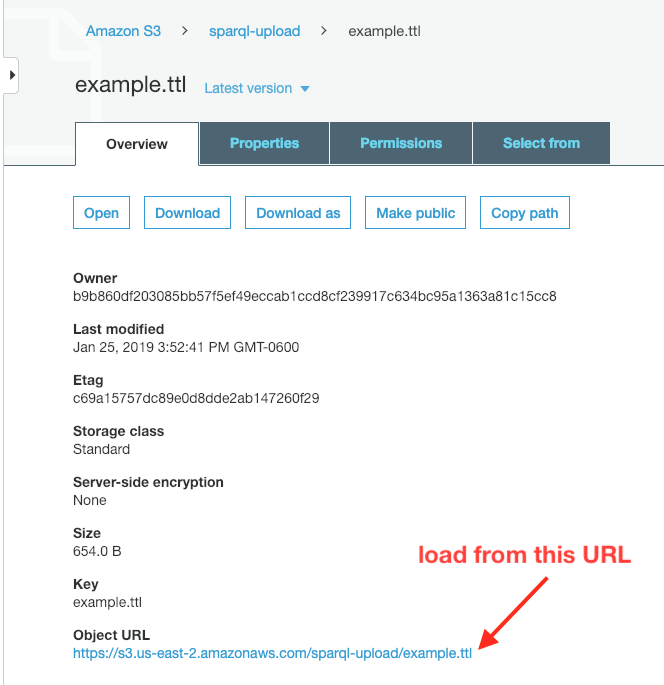
To carry out the LOAD command, use an application like Postman that can execute an HTTP POST request. A critical part is that the request must include a Content-Type header of application/sparql-update if the request file is plain text:
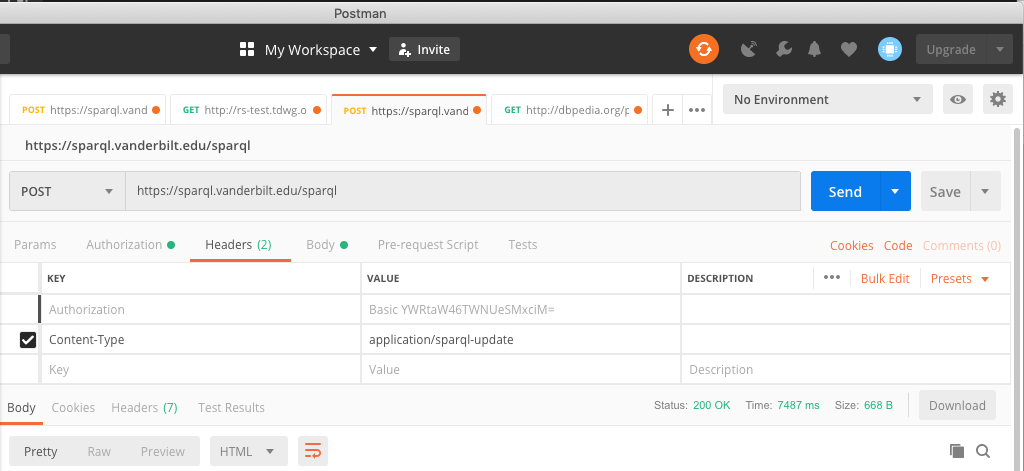
The body of the posted file should be plain text. The text should consist of a single line that is the LOAD command:
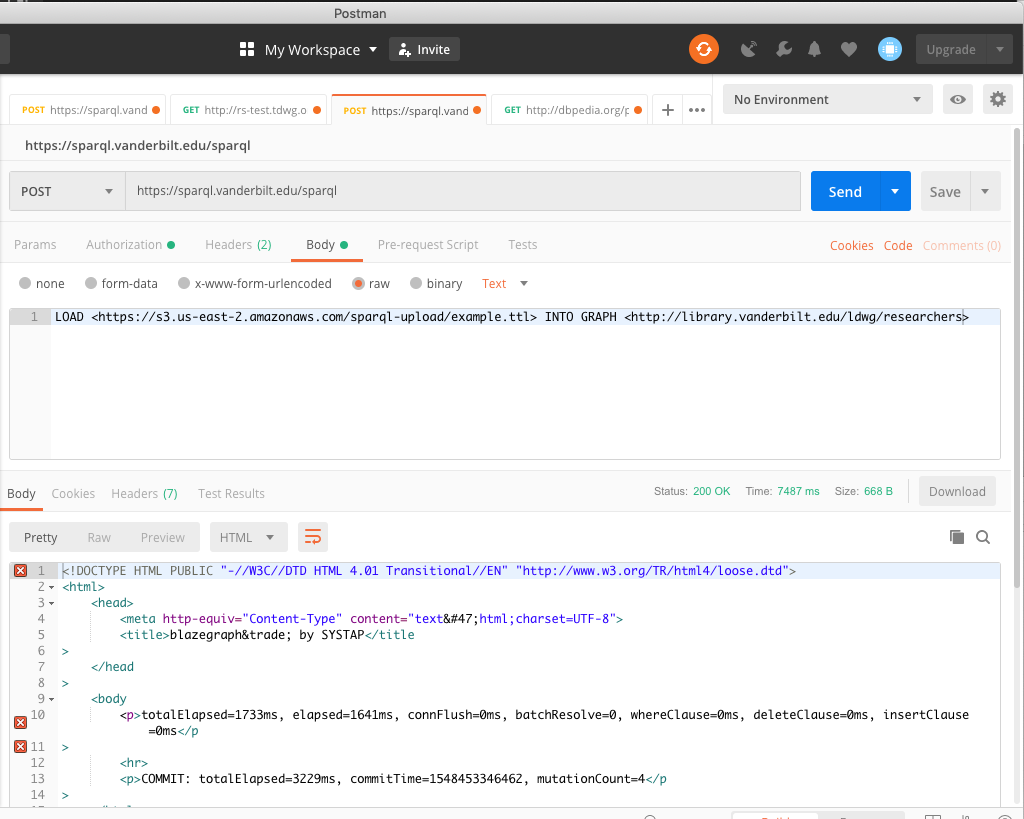
If the request is successful, the response body will indicate that the triples have been loaded. In this example, the “mutationCount” indicates that 4 triples were loaded.
We can show that the load was successful by a SPARQL query of the endpoint:
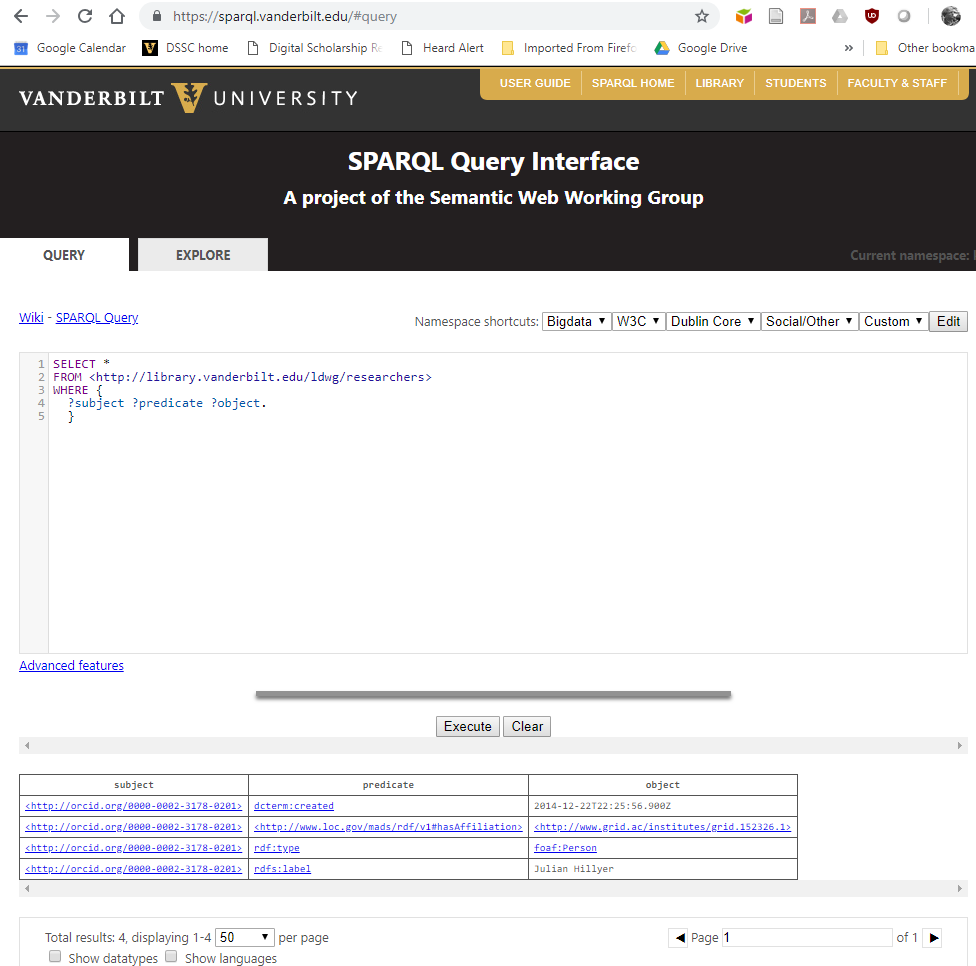
where we can see the four triples that were contained in the file that we loaded.
Although this method of loading triples into a graph seems like a lot more bother than using a GUI, it has two advantages. As mentioned before, you can choose the URI of the graph into which the triples are loaded. The other advantage is that you can script the process using any language that has the capability of making HTTP calls. So the process of loading files into the store could be automated.
Loading data using a software intermediary
In some cases, triplestores may have software that is designed to streamline the data entry process, either by providing a human-friendly interface, or by making it easier to import the data from other non-RDF sources.
An example of the first type of software is the web interface for adding to the Wikidata knowledge graph. The Wikibase system on which Wikidata is built uses the Mediawiki platform to create an interface that allows people to enter data accurately by providing a form that populates the fields with valid entries as the user types:
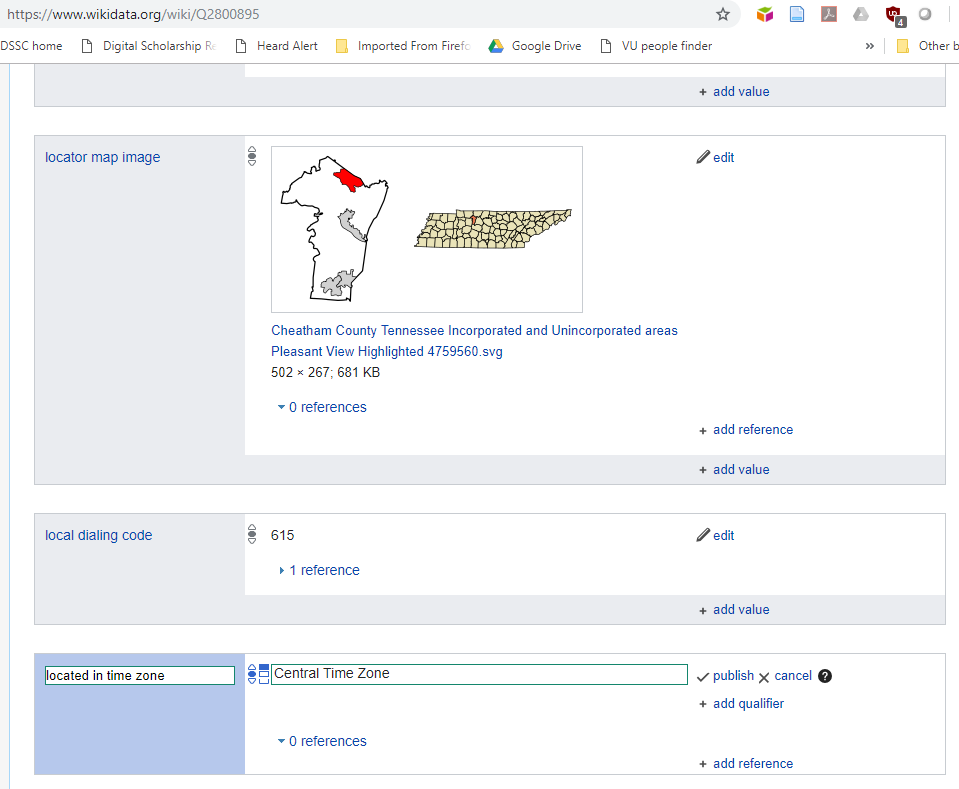
If we create a SPARQL for the timezone of Pleasant View, TN, we can see that the data we added using the form is now present in the triplestore:
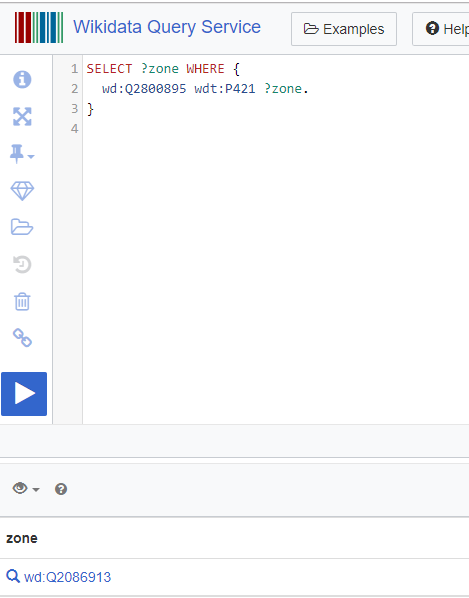
There are a number of software systems for adding bulk data to Wikibase, including Quickstatements and Python bots. We will explore some of these tools in future lessons.
Revised 2019-01-26

Questions? Contact us
License: CC BY 4.0.
Credit: "Vanderbilt Libraries Digital Lab - www.library.vanderbilt.edu"