Loading data into a wikibase using the VanderBot tool
VanderBot is a Python script that can be used to upload CSV data to Wikidata or any other wikibase instance. There are several blog posts and tutorials that explain how to use VanderBot to write data to the Wikidata test instance and to Wikidata itself. The focus of this page is using VanderBot to write to other wikibase instances, such as those on wikibase.cloud or Structured data on Commons.
With the advent of wikibase.cloud, the barrier to entry for setting up your own wikibase instance has been significantly lowered over setting one up yourself using Docker. With only a few button clicks, you can have a fully functioning wikibase with a functional Query Service to query its data. However, one of the drawbacks of setting up your own wikibase is that it starts out empty, meaning that you need to create all of the properties and items yourself. The main purpose of this page is to show you how you can quickly create large numbers of items with VanderBot using data in a spreadsheet.
The MediaWiki API
One of the reasons people like the Wikidata/wikibase ecosystem so much is that it has a really great graphical interface for editing. However, it requires many button clicks to edit, so for mass editing many users graduate to some other tool like QuickStatements or OpenRefine. These tools all write to the underlying database that supports wikibase via the MediaWiki API that exists for all wikibase instances. It is quite painful to interact directly with the API without some software tool, but if you are interested in those sorts of details, see “The MediaWiki API” section of this blog post. We will avoid some of that pain by using the VanderBot script, which mediates the interactions with the API for you. (Another alternative is to use the Pywikibot Python library. For more information about that option and the problems associated with it, see this page)
Set up a bot password
To write to any wikibase, you need to have credentials that can be used to give you write permissions. The process of acquiring these credentials is called “creating a bot password” because they are used by people who create autonomous bots to perform automated editing. Even though we aren’t performing automated editing, the process of generating those credentials is the same. NOTE: a bot password gives anyone the ability to make edits under your account! So never include the password in code that you publish or push the credentials to a public repository like GitHub. The advantage of using bot password can be revoked if it’s compromised without having to shut down your whole account.
Downloading the template credentials file
Open this page in a new tab in your browser. Right-click on the Raw button in the upper right of the screen and select Save Link As.... Navigate to the directory where you want to put the script and save the file there. These examples assume that you have stored the credentials in your home directory, so save it there unless you have reasons to do otherwise.
Using a text editor (like TextEdit on Mac, Notepad on Windows, or your favorite text or code editor that is NOT Microsoft Word), open the wikibase_credentials.txt file that you just downloaded. Leave the file open as you go to the next step.
Create a bot password
The screenshots here show how to create a bot on a wikibase instance that was hosted on AWS (hence the 18.205.159.211:8181 IP address), but they are the same for any wikibase. Start by logging into whatever wikibase you want to interact with. NOTE: API credentials go across the Wikimedia universe, so if you have an account for Wikipedia, Wikimedia Commons, or the real Wikidata, you can use it to log into any of them to create the credentials to write to any of those platforms (and the Wikidata test instance as well).
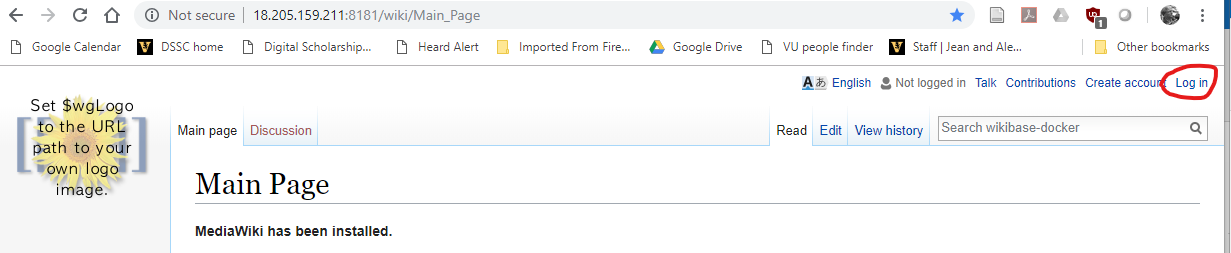
1. In the upper right, click on the login link. If you’ve set up an account on wikibase.cloud, as an administrator you should be able to create a user acount that’s separate from your administrator account. You should use a regular user account when you set up the bot password. You can also create a user account by clicking on the button under Don't have an account?.
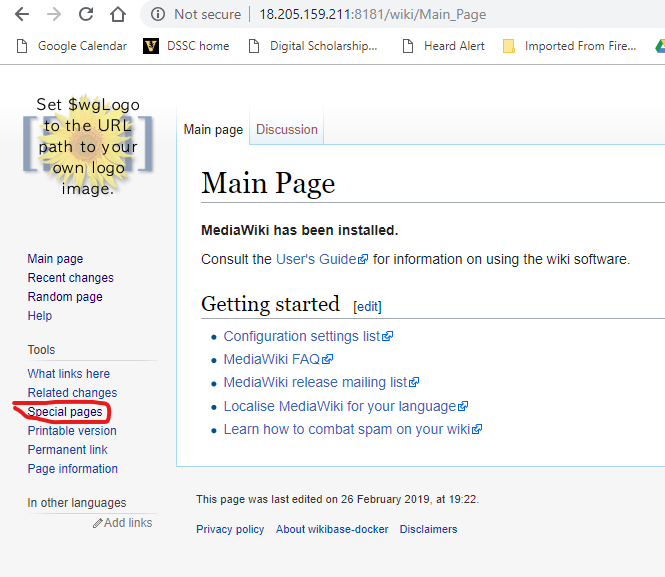
2. After you have logged in, click on the Special pages link in the left menu.
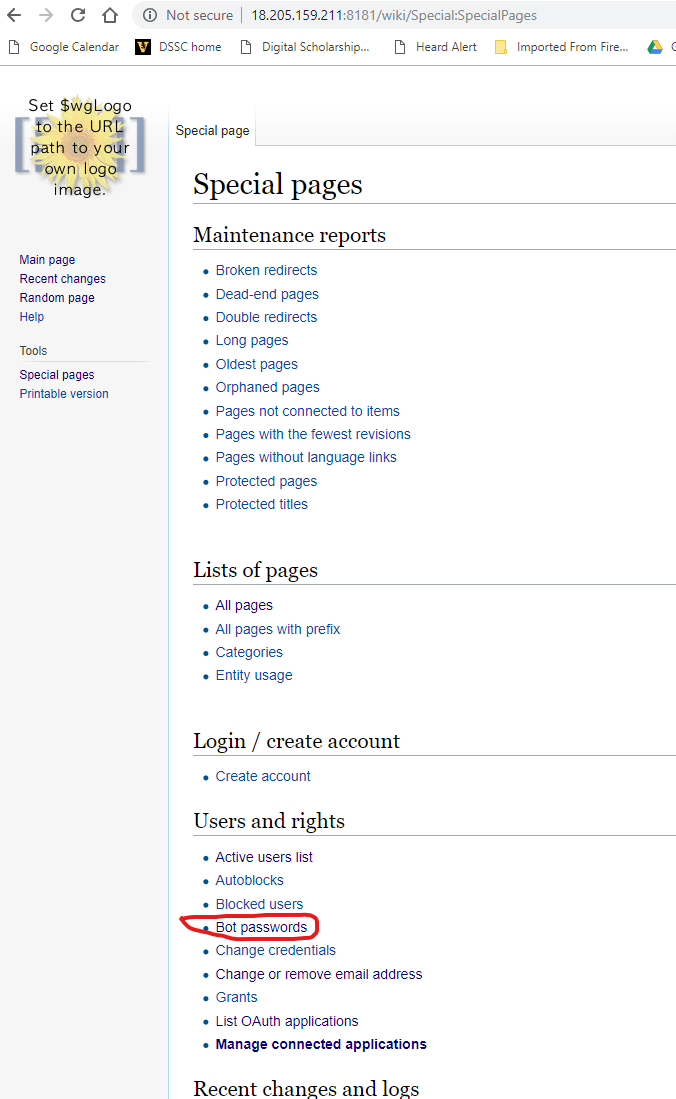
3. On the Special Pages page, click on the Bot passwords link.
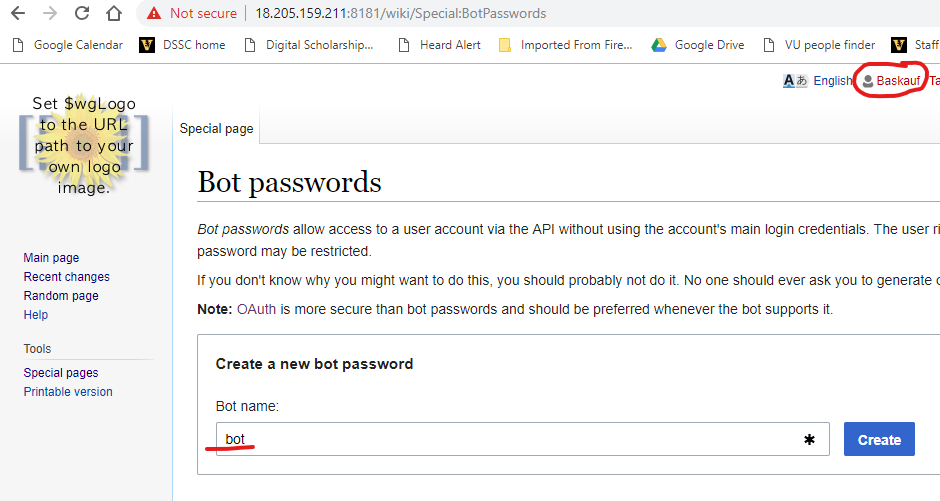
4. On the Bot passwords page, enter the name of your bot. It is customary to include the text bot somewhere in the bot’s name. You don’t need to worry about your bot’s name colliding with other bot names because edits will actually be associated with your user account and not the bot name.
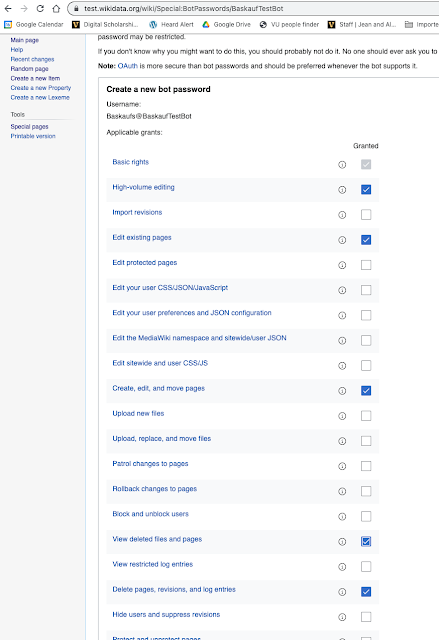
5. Check the boxes for permissions to give to your bot. I think the important ones are Edit existing pages, Create, edit, and move pages, and Delete pages, revisions, and log entries. However, just in case, I also selected High-volume editing, and View deleted files and pages as well. Click on the Create button.
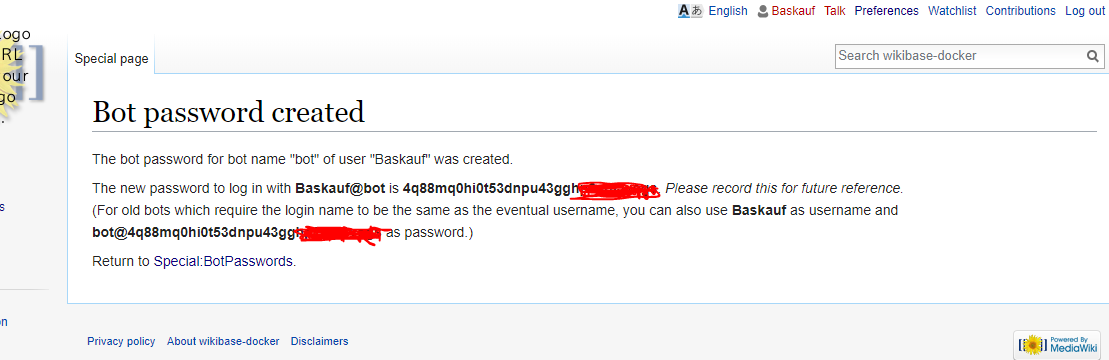
6. A password will be created for your bot. As the text indicates, there are actually two versions of the username and password. Use the first username where the username contains “@”, along with its corresponding password.
Save the credentials
In the credentials file that you left open before, copy and paste your bot’s username in place of User@bot in the credentials file. Copy and paste your bot’s password in place of the example password in the credentials file. Make sure that you don’t have any trailing spaces after the username and password, or between the equals sign and the text you pasted in.
The first line of the file contains the base URL for the wikibase instance that you used to create the bot password. In the example file, the URL is https://wbwh-test.wikibase.cloud. If you are also running a wikibase out of wikibase.cloud, your URL will have a subdomain that’s different from wbwh-test. When you replace this URL in the file, make sure that you DO NOT include a trailing slash or any trailing spaces.
Save this file as plain text. If you downloaded it into your home directory, it should already be in the right place.
There is no way to recover credentials once you leave the page, so it might be good to save another copy of the file under a different file name in case you accidentlly write over or delete this one. Of course, you can also just delete this bot password and generate a new one if necessary.
Properties in the wikibase
If you are already familiar with properties in Wikidata, you may be annoyed to discover that there is not necessarily any relationship between property P IDs in any particular wikibase and the familiar P IDs in Wikidata. For example, P31 (“instance of”) is one of the most important properties in Wikidata. But a particular wikibase may have a different P ID for “instance of” or the property may not exist at all.
The development of tools to transfer some or all properties from Wikidata to a wikibase is a topic of active interest as of 2023-02-07. For now, we will manually create the properties we need using the graphical interface. For information about a tool to create properties in a generic wikibase see this page.
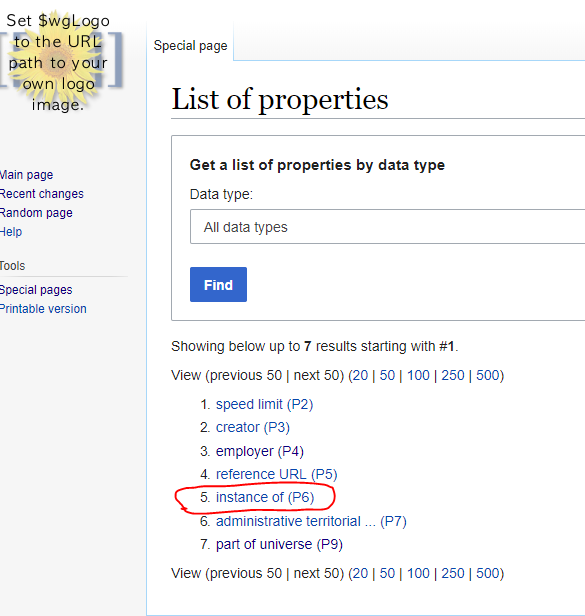
To see the available existing properties, go to Special pages then List of properties in the Wikibase section.
Adding properties
If a property that you want to assign to the items that you want to add doesn’t exist, you will need to create the property by going to Special pages, then Create a new property in the Wikibase section.
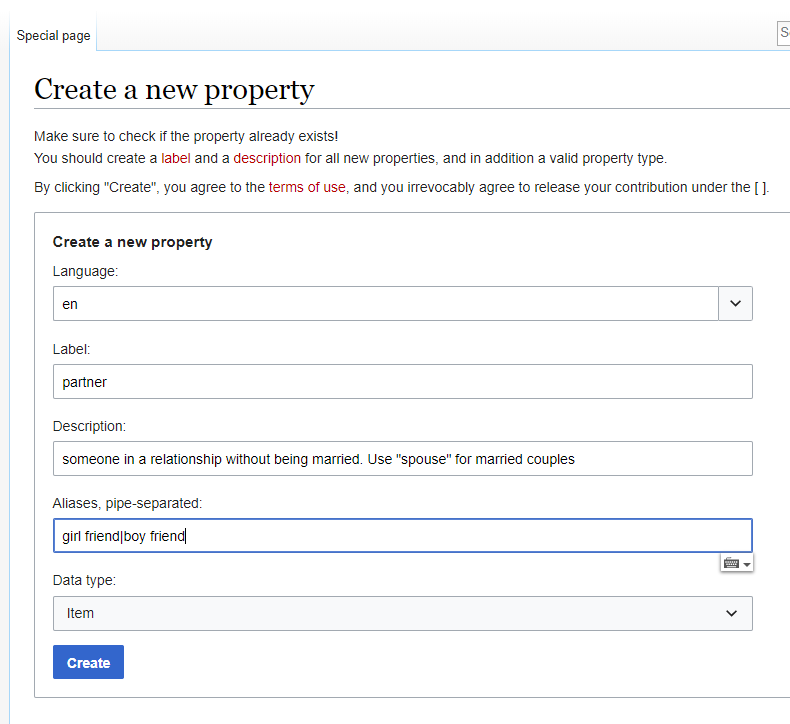
In this example, I created a property to link items for Mickey and Minnie Mouse. Selecting the correct Data type is important. The following datatypes are supported by VanderBot: Item, String, URL, Monolingual text, Geographic coordinates, Point in time, and Quantity.
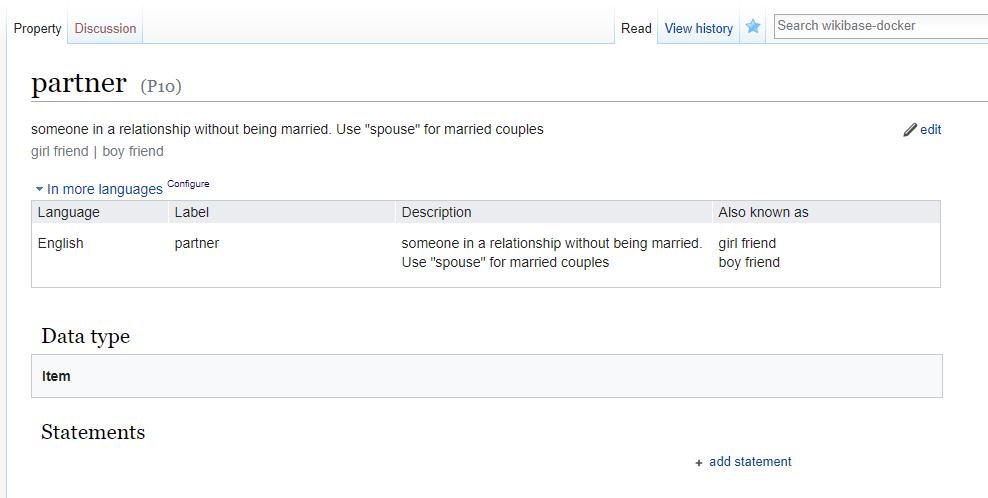
When I click Create, I see the page for the newly created property.
The config.yaml mapping file
The easiest way to create the mappings between the property IDs used to describe items and the columns in the CSV file containing the data is to create a config.yaml file. This file can be used both to generate appropriate column headers and to download existing data.
Describing the property/column header mappings
Here is an example of a YAML mapping file, which can also be downloaded from here:
data_path: ""
item_pattern_file: graph_pattern.txt
item_source_csv: ""
outfiles:
- output_file_name: statues.csv
label_description_language_list:
- en
- fr
manage_descriptions: true
# Note: if no columns to ignore, you must omit the "ignore" key or provide an empty list value: []
ignore: []
prop_list:
- variable: instance_of
value_type: item
pid: P1
qual: []
ref: []
- variable: artist
value_type: item
pid: P2
qual:
- variable: series_ordinal
value_type: string
pid: P3
ref:
- variable: reference_url
value_type: uri
pid: P4
- variable: retrieved
value_type: date
pid: P8
- variable: height
value_type: quantity
pid: P5
qual: []
ref: []
- variable: gps
value_type: globecoordinate
pid: P6
qual: []
ref: []
- variable: title_en
value_type: monolingualtext
language: en
pid: P7
qual: []
ref: []
This example includes examples of all of the datatypes supported by VanderBot. For more details about formatting these files, see this page. For now, we can ignore the first three lines of the script. The mapping configuration file can support mapping multiple CSV files, but in this simplified example we are only using one (statues.csv). The important part here is the prop_list section, which describes a list of statement properties, each indicated with a dash. The variable key provides the root name for columns associated with that property. The value_type indicates which of the seven supported value types is required for that property. (Note that there are slight differences in the spelling and capitalization from the dropdown list in the graphical interface.) Depending on the type, there could be one to several columns necessary to fully describe the value. The pid is the P identifier that is appropriate for that particular wikibase, which may differ from the P ID in Wikidata. No P ID may be represented more than once among the statement properties.
Each property may have zero to many qualifier and reference properties associated with it. Although it is theoretically possible to have multiple reference per statement (corresponding to a property here), for simplicity this mapping system only supports one reference per property. If a given statement property has no qualifier properties or no reference properties, an empty array ([]) must be given as the value.
Generating column headers and the csv-metadata.json file
Once the config.yaml file has been created, it can be used to generate two files needed to do the upload to the API. One file is the more complex csv-metadata.json file used to describe the table according the the W3C Generating RDF from Tabular Data on the Web Recommendation. This file is require by VanderBot. The other file is the CSV that contains the data. Both the csv-metadata.json file and column headers for the CSV can be generated from the config.yaml file using the script convert_config_to_metadata_schema.py described here.
Running that script with the example file above generates the csv-metadata.json file and the file hstatues.csv. The latter file name differs from the file name given for the output_file_name in the config.yaml file by having an “h” (for headers) prepended to the name. This is to avoid overwriting any existing data files with the same name. If you are creating a new CSV that you want to fill in with data, just remove the “h” from the filename.
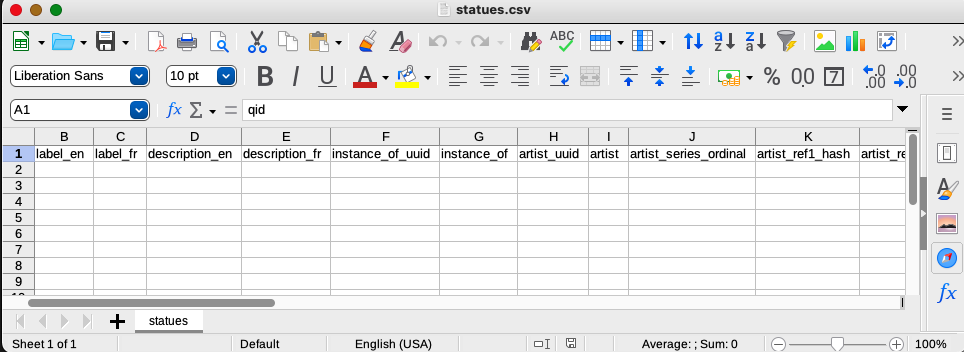
When I open the file with a reliable CSV editor (like Libre Office which for technical reasons is the only one I recommend to use), I see that the left side of the spreadsheet has columns for labels and descriptions in the languages I specified. In addition to the instance_of and artist columns that I specified, there are two columns used to store the statement UUID identifiers that will be generated when the data are uploaded to the API. The artist_series_ordinal column holds the value for the series ordinal qualifer that I associated with the artist property.
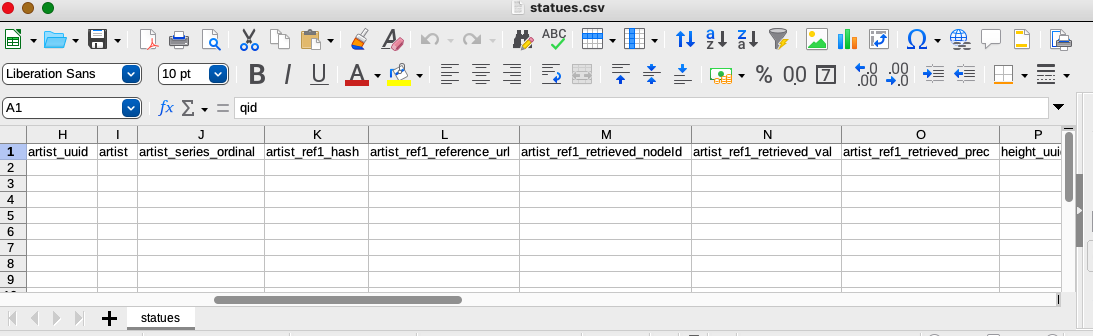
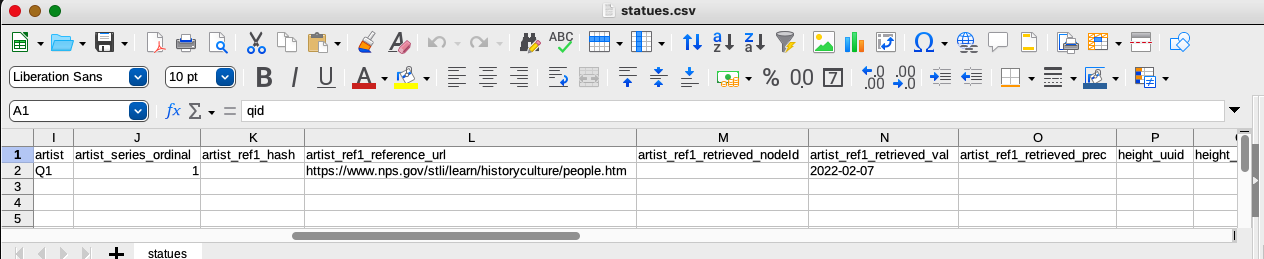
The column headers associated with the artist reference that I described in the mapping configuration are more complicated because the API generates an identifier specifically for the reference (artist_ref1_hash), and because the datatype (date) is a complex value type that requires two values (artist_ref1_retrieved_val and artist_ref1_retrieved_prec) to describe the time and precision of the date. A node ID (artist_ref1_retrieved_nodeId) for the complex value will be filled in by the script.
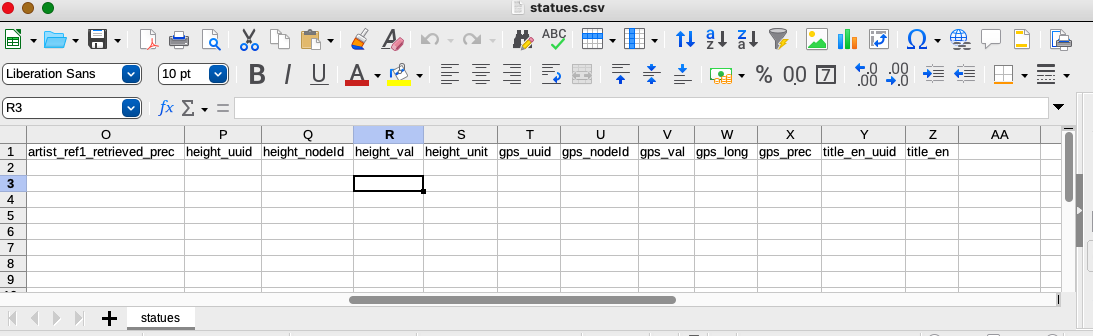
Values for the height and gps properties are similarly complex, requiring two values to describe the magnitude and units for height and three values for gps (to describe the latitude, longitude, and precision).
Entering the data
The raw data can now be entered in the CSV
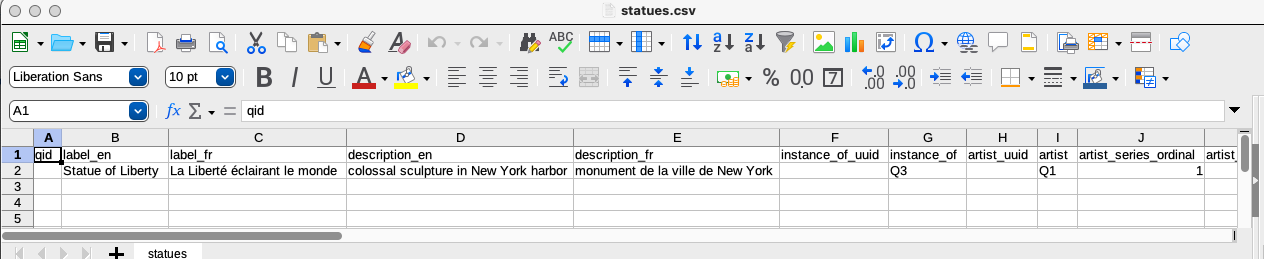
Values that are items must be given as Q IDs (including the “Q”).
Dates should be given as ISO 3601 dates in either YYYY-MM-DD, YYYY-MM, or YYYY format. The precision can be left blank and VanderBot will figure it out from the format you use.
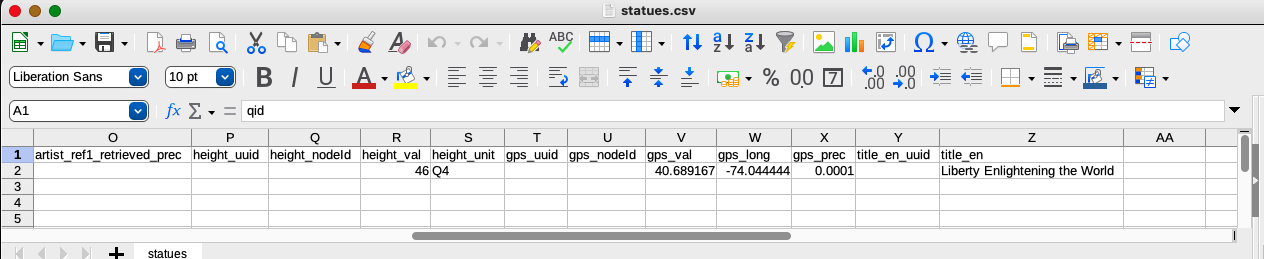
Quantity value types must include a unit value given as a Q ID. That Q ID must be from the wikibase being written to and not the Wikidata Q ID for the unit. The language of monolingual text values is not specified in the data CSV because it’s given in the mapping file. Here’s a link to the CSV with the raw data.
Some datasets to play with uploading
There are two directories that have config.yaml mapping files and some raw data to populate generated CSVs with: chemical element data and data about states in the United States. Before uploading these data as items in your own wikibase, you will need to create properties with appropriate value types to match those listed in the mapping files, and change the P IDs in the mapping file to match those properties.
You also will need to create items to use as values for some of the properties that require items as values. Notably, the capital column in the states table requires item values. So first you should use the config_capital.yaml file to create corresponding capital items, then paste their Q IDs into the capital column of the states table.
Uploading the data
Once the data have been entered into the spreadsheet, make sure that it, the csv-metadata.json file, and the VanderBot python script are in the same directory. Open a terminal window and navigate to the directory where you put the files.
If you used the default file names and if your credentials are in your home directory, you can just run the script in a termal window (changed to the directory in which the files are located) using the command
python vanderbot.py -D false -A 0
In some installations, it may be necessary to use python3 instead of python in the above statement.
The -D option suppresses checking for duplicate label/description combinations, which requires using the wikibase SPARQL endpoint. (More on this later.) Providing a zero value for the -A option sets the API delay value to zero seconds. When writing to the Wikidata API, writing more than 50 edits per minute without a bot flag will cause you to be blocked for some period of time. When writing to your own wikibase instance, there is no reason to observe any delay.
If you deviated from any of the defaults or put the credentials file somewhere else, use command line options as necessary.
If the write to the API is successful, a new item will be created:
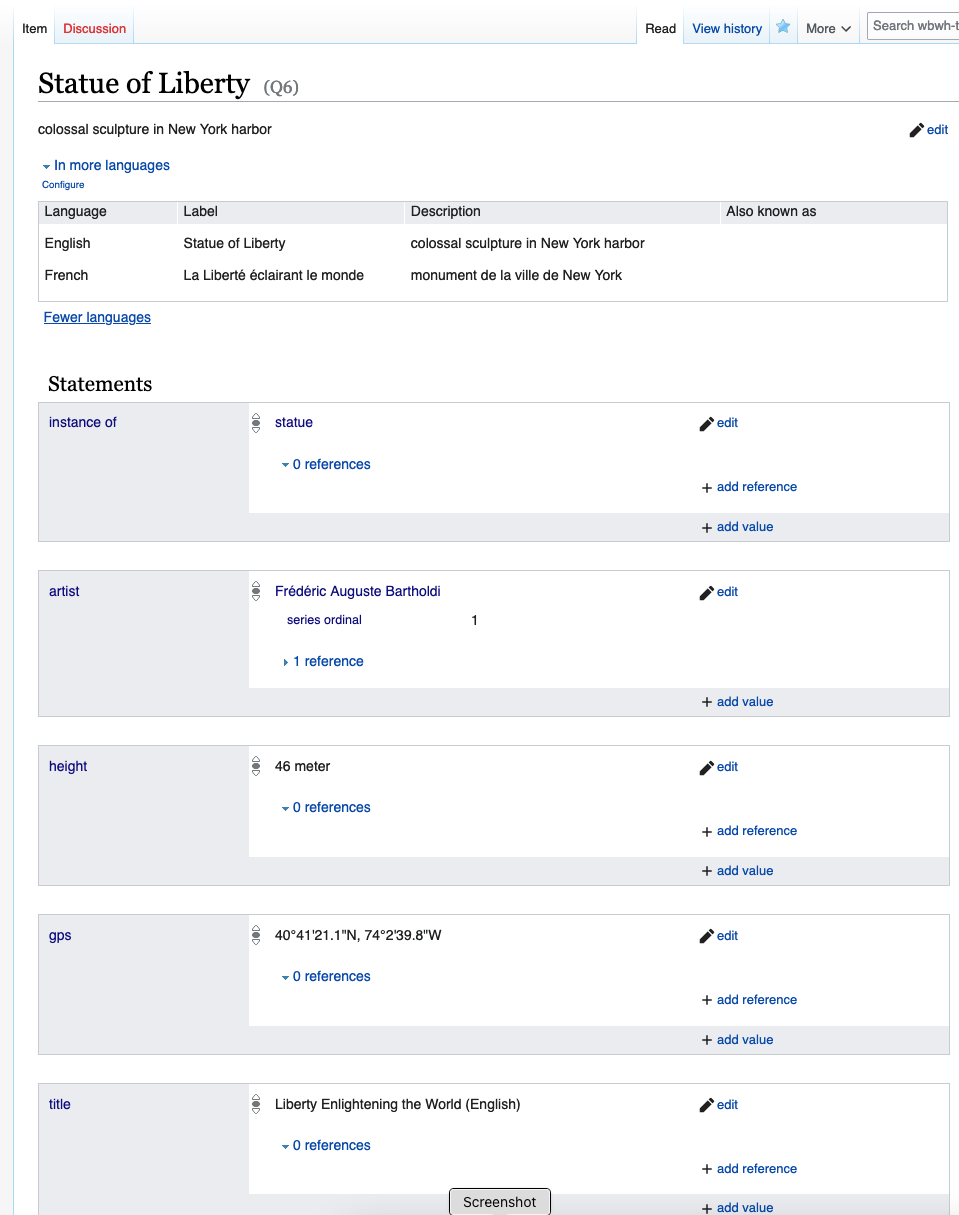
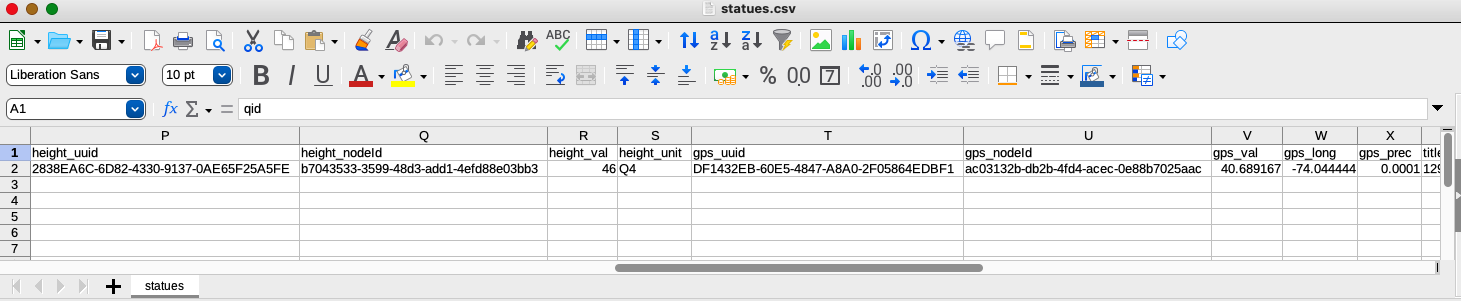
If we re-open the CSV, we can see that the VanderBot script has filled in many IDs that were assigned by the API
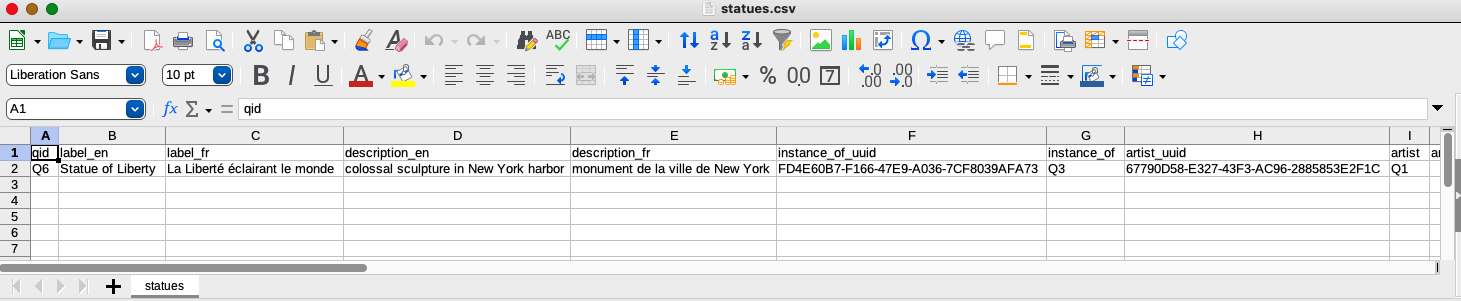
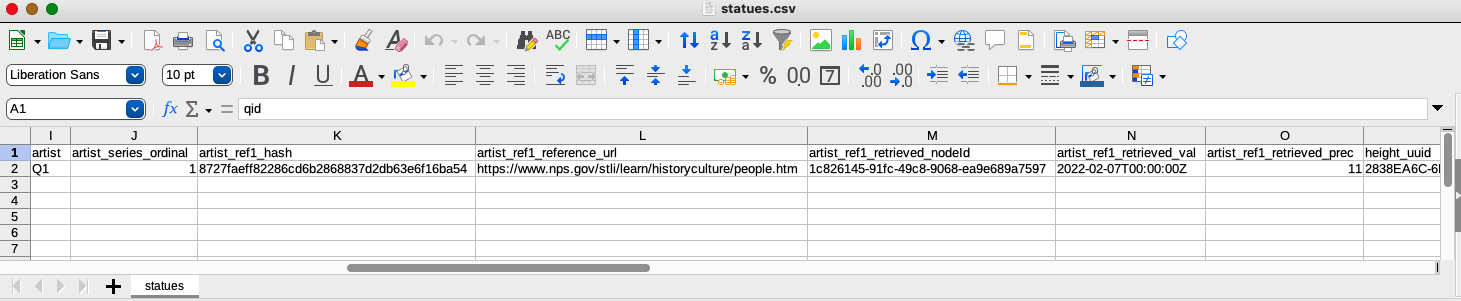
Notice that VanderBot has converted the simple ISO 3601 dates to the more complex values required by the API and added an appropriate precision for the date in the artist_ref1_retrieved_prec column.
Adding data to existing items
The VanderBot script can also create new statements for items that have already been created. In rows having a value in the qid column, if data are added to a property column that had previously been empty, the script will create a statement for that property. If reference columns associated with that property column also have data, those references will be created at the same time as the statement.
References can be added in cases where a reference column was previously empty while the corresponding property column had a value. Simply add the reference data and run the script again.
In the case where statement values or reference values need to be changed, they must first be removed using VanderDeleteBot. Then the new values or references can be added.
Qualifiers cannot be added independently of their associated statements. To add or change qualifiers, delete the statement using VanderDeleteBot and recreate the statement with the new qualifier data.
Using the SPARQL endpoint with VanderBot
VanderBot has several functions that use the wikibase SPARQL endpoint to perform data checks. The Query Service for a wikibase.cloud instance is much slower than the Wikidata Query Service, so using these functions can significantly slow down writing to the API and you might want to disable them.
If you do want to use those features, you need to provide the URL of your instance’s endpoint. You can find the base URL by clicking on the Query Service link on the left panel. That will take you to a new URL of a form like this: https://wbwh-test.wikibase.cloud/query/. To form the SPARQL endpoint URL, append sparql to this URL. In this example the endpoint URL becomes https://wbwh-test.wikibase.cloud/query/sparql.
When using the features that need to check the Query Service, add the -E option to the command for running VanderBot. In the following example, checking for duplicate label/description combinations is enabled by default (no -D option necessary):
python vanderbot.py -A 0 -E https://wbwh-test.wikibase.cloud/query/sparql
Note: checking for duplicates should NOT be disabled when working with Wikidata because you must take care to not create duplicate items.
Another function that uses the Query Service is allowing automatic updating to labels and descriptions. By default, labels and descriptions are only written for new items. Labels and descriptions of existing items are left unchanged. If the -U option is set to allow, any changed labels or descriptions will be written to the API. In that case, the script uses a SPARQL query to download all of the existing labels and descriptions so that it can determine whether they have changed or not. So for non-Wikidata wikibases, the -E option must be used to specify the SPARQL endpoint in order for the -U option to work.
The third circumstance where the Query Service is used is in cases where aliases are included. This requires a hack to the csv-metadata.json file that isn’t supported by this work flow, so most users can disregard this.
Downloading existing data
The config.yaml mapping file can also be used to download existing data from a wikibase. This can be done with the acquire_wikidata_metadata.py script, which is described in detail here. The strategy that we will follow here is to create a second config.yaml file whose P IDs are the ones from Wikidata that are analogous to the ones we created in our wikibase and have used in the first config.yaml file. To keep the two files straight, I’m calling the second one config_wikidata.yaml.
Here’s what that mapping file would look like:
data_path: ""
item_pattern_file: ""
item_source_csv: qids.csv
outfiles:
- output_file_name: statues_downloaded.csv
label_description_language_list:
- en
- fr
manage_descriptions: true
# Note: if no columns to ignore, you must omit the "ignore" key or provide an empty list value: []
ignore: []
prop_list:
- variable: instance_of
value_type: item
pid: P31
qual: []
ref: []
- variable: artist
value_type: item
pid: P170 # creator
qual:
- variable: series_ordinal
value_type: string
pid: P1545
ref:
- variable: reference_url
value_type: uri
pid: P854
- variable: retrieved
value_type: date
pid: P813
- variable: height
value_type: quantity
pid: P2048
qual: []
ref: []
- variable: gps
value_type: globecoordinate
pid: P625 # coordinate location
qual: []
ref: []
- variable: title_en
value_type: monolingualtext
language: en
pid: P1476
qual: []
ref: []
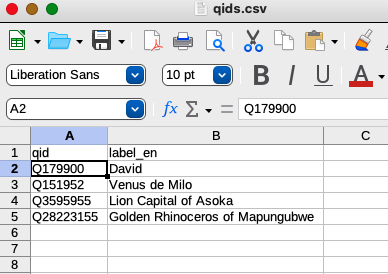
If you look carefully, you will see that this file is slightly different from the original config.yaml file. In addition to having P IDs that come from Wikidata, the item_pattern_file value is set to an empty string and the item_source_csv value designates a CSV spreadsheet that indicates the items for which metadata is to be downloaded. This spreadsheet must contain a column whose header is qid. Any other columns will be ignored. In this case, the qids.csv file contains the Q IDs of some famous statues:
Another alternative to explicitly providing the Q IDs in a spreadsheet is to specify a SPARQL graph pattern that will bind a set of Q IDs based on criteria expressed in the pattern. Here is an example:
?qid wdt:P31 wd:Q860861.
?qid wdt:P195 wd:Q18563658.
The first triple pattern requires that the item be an instance of sculpture. The second triple pattern requires that the item be part of the Vanderbilt Fine Arts Gallery collection. If you use this method, the pattern must be saved in a plain text file and the file name provided as the value of item_pattern_file. For details see this page.
In the config_wikidata.yaml file, I also changed the output_file_name to statues_downloaded.csv to avoid damaging the existing statues.csv file that contains my original data on the Statue of Liberty. The script will create statues_downloaded.csv since it doesn’t already exist.
To run the acquire_wikidata_metadata.py script using the second configuration file, use the command:
python acquire_wikidata_metadata.py -C config_wikidata.yaml
using the -C option to specify a configuration file name different from the default config.yaml. Here’s what I get:
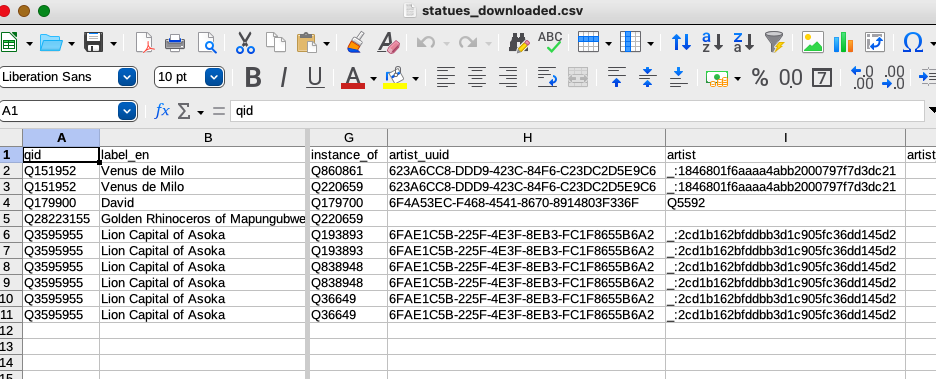
You can see that there were multiple results for several of the statues. That’s because the SPARQL query results include every combination of values. Venus de Milo has two “instance of” values and the Lion Capital of Asoka has three. Since I’m going to assign my own “instance of” (P1) value in my wikibase, I don’t care about the multiple values so I’ll just delete the multiples.
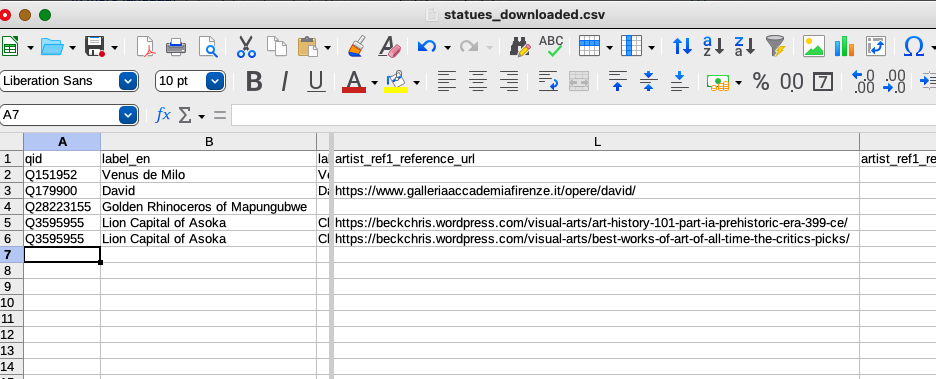
Scrolling to the reference URL, I see that two were provided for the Lion Capital of Asoka. I only want one, so I’ll pick the one I want to use and delete the other line. Here’s a link to what the CSV looks like with the extraneous rows removed.
Because the column headers match my original table exactly, I’ll copy and paste the downloaded cells into my original table.
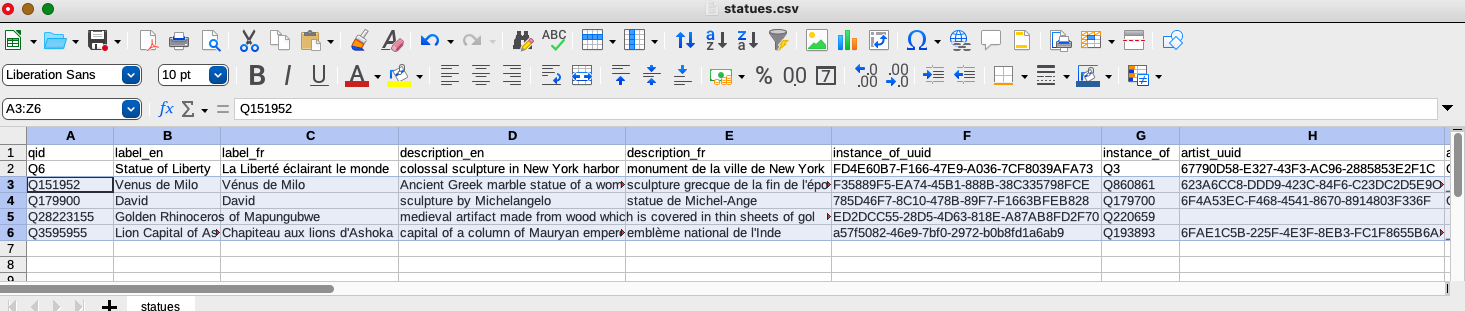
To upload into my wikibase, I need to:
- delete all of the Wikidata-assigned identifiers: the item qid, the claim UUIDs, the reference hashes, and the node IDs for complex values.
- I will paste
Q3in all of theinstance_ofcells. - I don’t have an item for Michelangelo in my wikibase, so I need to create that and substitute it for
Q5592in theartistcolumn. The blank node identifiers for the anonymous artists are OK, so I will leave them (see this for more details about modeling anonymous artists). - The
height_unitvalues from Wikidata are the Q ID for centimeters, so I need to create an item for that and change the Q IDs to the centimeter item in my wikibase.
Here’s what the spreadsheet looks like when it’s ready to upload:

I can now use VanderBot to do the upload as I did previously. Here’s the result for Lion Capital of Asoka:
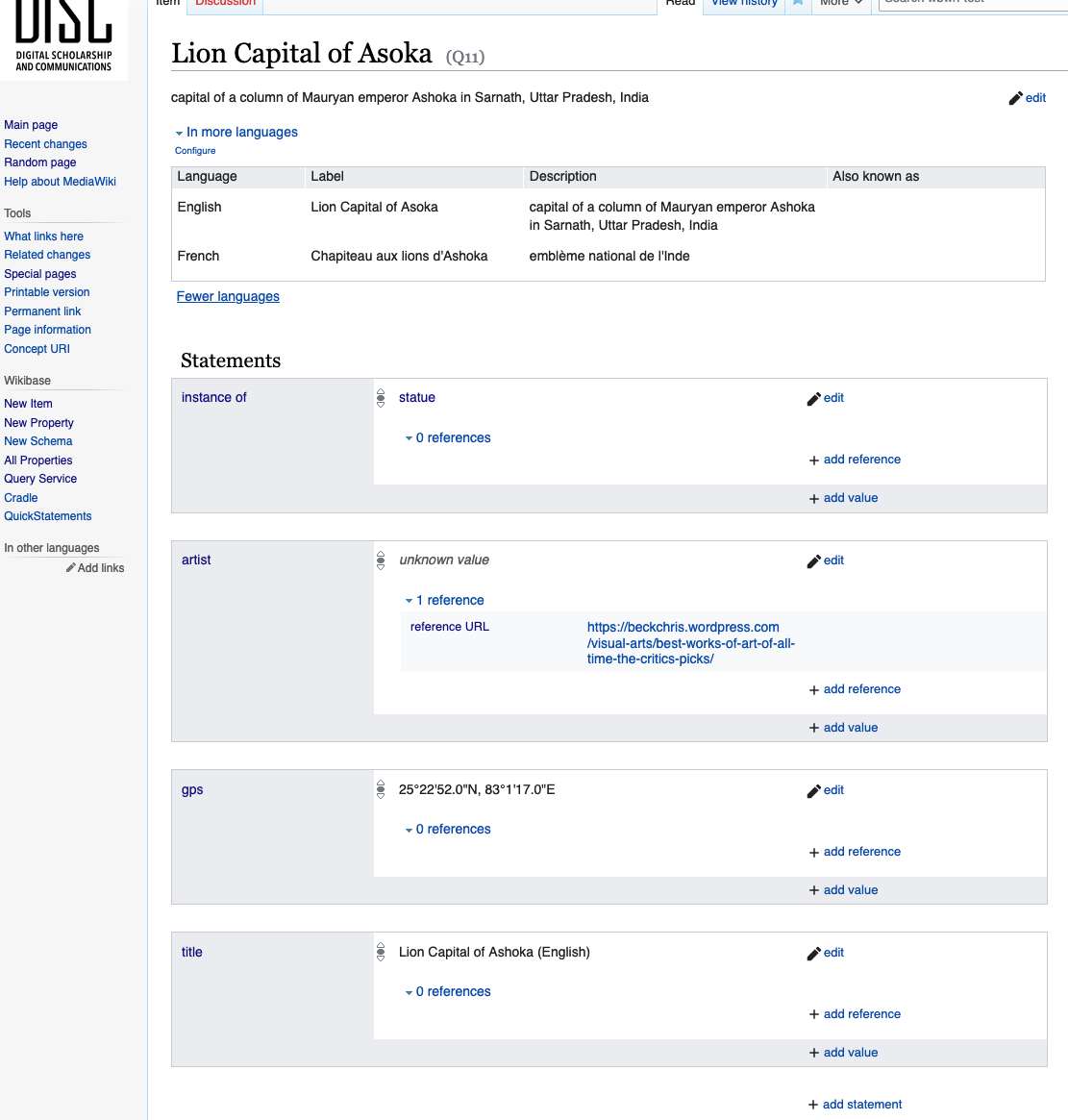
Here’s a link to the CSV after the upload where all of the identifiers assigned by the API have been added to the table.
deleting statements and references
creating properties using a script
querying a wikibase with SPARQL
interacting with Structured Data on Commons
Revised 2023-02-11

Questions? Contact us
License: CC BY 4.0.
Credit: "Vanderbilt Libraries Digital Lab - www.library.vanderbilt.edu"