Note: This tutorial assumes that you have a basic understanding of basic Linked Data and RDF terminology. If necessary, review the lessons on graphs, URIs, and triples and serilizations and triplestores before proceeding.
SPARQL
SPARQL is a recursive acronym for SPARQL Protocol and RDF Query Language. Its name provides some clues about what it’s for. SPARQL is at its core a query language. It allows users to query RDF triples that are stored in a graph database. But it has other pieces as well. SPARQL Update allows users to manage data in a triplestore, such as adding or deleting triples or entire graphs. It is also a communications protocol that specifies how a client (software on a local computer) should interact with a server (remote computer) through HTTP when the client wants to perform either a query or update operation.
The name SPARQL suggests similarities with SQL, a common query language for relational databases. However, SPARQL queries have some features that are intimately related to the graphs contained in the triplestore.
Important general note: Generally, SPARQL is not case sensitive with respect to the keywords. However, variable names and URIs ARE case sensitive, so use care to be consistent with them. Also, SPARQL is generally not picky about whitespace, so you can use line breaks and indentation to make the queries more readable.
Graph patterns
A fundamental feature of both SPARQL queries and updates is the graph pattern. A graph pattern describes the circumstances in the data that must be satisfied in order to achieve a solution to the query. The pattern that is specified is describes the parts of the graph structure in which we are interested, so it isn’t really possible to write a graph pattern without being aware of the model that underlies the graph of interest.
In the following examples, we’ll use the graph model and data from earlier lessons.
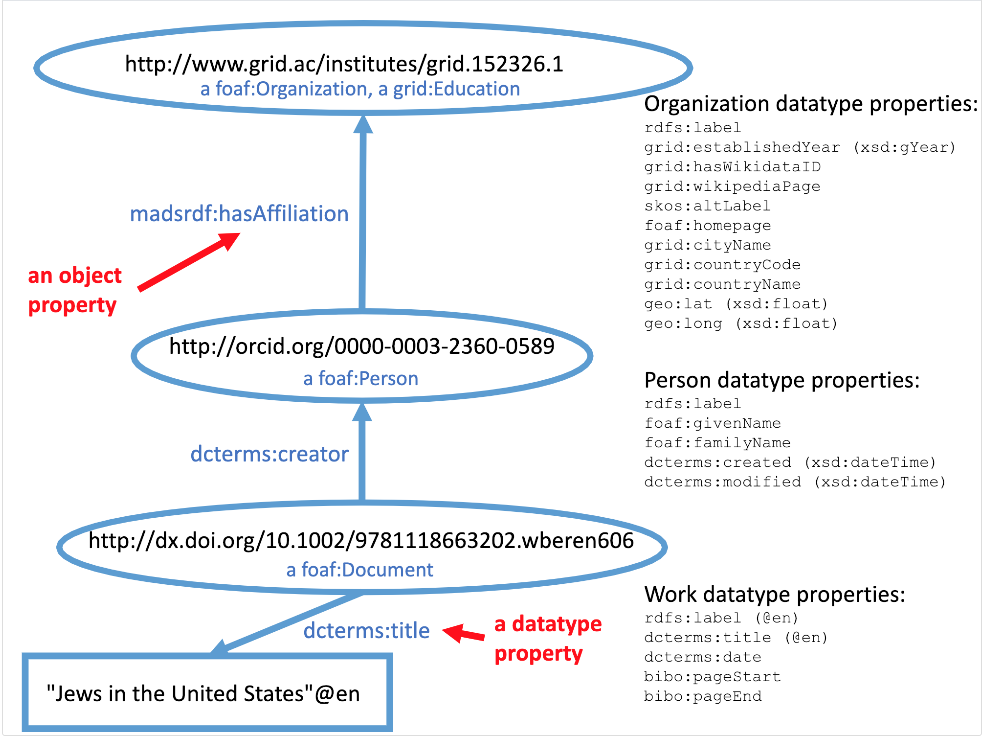
The diagram above shows how three classes of things are related to each other. (For a larger view of the model, view this PDF). Although each bubble representing a class in the model is labeled with the URI of a particular instance, the bubble represents the class in general. The next diagram shows a diagram of the actual graph itself, and includes all of the specific data we can query.

Notice that in contrast to the general model of classes, this diagram shows every instance of each class: one organization, two people, and five documents. In graph terminology, each of these URI-identified “bubbles” representing core resources are called nodes. They are, in turn, connected to many literal nodes (represented by rectangles) that contain text strings that describe the nodes they are connected to. There are also three important bubbles that tell the class to which the core resources belong. They are connected by rdf:type links (abbreviated as a in the graph model).
In general, we can refer to each circle or rectangle as a node, and each arrow as an edge. In RDF terms, the edges are called predicates (which you can also consider to be synonymous with properties).
We could describe a simple graph pattern in words: “what are all of the cases where a subject node is connected to an object node by a dcterms:creator predicate?” By examining the diagram, we can see that there are five arrows that fit the pattern: one for each time a document is connected to a person. We can say that there are five solutions that satisfy this graph pattern.
We can make the pattern more specific. We could say, “what nodes are the objects connected to a subject node by a dcterms:creator predicate, where the subject node is also connected to an object by a dcterms:title predicate to a text string that is ‘Let My People Go’ ?” This further limits the solution to the previous graph pattern, because although there are five situations where documents are connected to people, only one of those documents is also connected to a node with the text “Let My People Go”. So the node we are interested in is the one with the label “Shaul Kelner” (i.e. the node that represents the person whose name is “Shaul Kelner”).
Writing graph patterns as triple patterns
As you can see, it can quickly get messy to try to describe the graph patterns in words. It is easier to describe the graph pattern using a notation similar to the Turtle RDF serialization. The overall graph pattern is enclosed in curly brackets, and the pattern is described by listing each of the triple patterns that describe the links between the nodes we are interested in. For example, here is the graph pattern for the first example:
{
?document dcterms:creator ?person.
}
SPARQL does not care about whitespace, so we could have crammed the whole graph pattern onto one line instead of putting the curly brackets on separate lines. But it’s easier to read this way, especially when the graph pattern contains more than one triple pattern.
Notice that the triple pattern contains variables (beginning with question marks):
?document and ?person. The variables can take any value that satisfies the pattern. Since there are five triples (subjects connected to objects by predicate arrows) in the solution, we can say that there are five sets of subjects and objects that can be bound to the two variables. The names that we use for the variables are arbitrary. We would get the same result if we used the pattern
{
?a dcterms:creator ?b.
}
But it’s easier to keep track of what the variables represent if we use names for them that are descriptive. The predicate dcterms:creator is a compact URI (CURIE) abbreviation of the full URI http://purl.org/dc/terms/creator. In order to use abbreviations such as this, we need to list the abbreviations used in the query in the prolog. There will be an example of this later.
We could have also listed the full URI if we use the angle bracket notation of Turtle:
{
?document <http://purl.org/dc/terms/creator> ?person.
}
Here’s what the graph pattern would be for the second example:
{
?document dcterms:creator ?person.
?document dcterms:title "Let My People Go"@en.
}
Notes:
- In the RDF, the book title has an English language tag. We must include this in the triple pattern or we won’t get a match. There is a way around this, but we won’t get into that now.
- In this query, the
?documentvariable is a sort of “dummy” variable. We don’t actually care what it is – we just need to refer to it because it’s the connecting node between the title and the person we are trying to find. - In this case, the solution to the graph pattern that we care about is the URI that gets bound to the
?personvariable.
Restricting by type
A common triple pattern used in graph patterms is to say that a resource must be an instance of a particular class. Since rdf:type is used to indicate a class of which a resource is an instance, we can use rdf:type (or its abbreviation a) as the predicate in a triple patterm. Here’s an example:
{
?resource a foaf:Document.
?resource rdfs:label ?articleLabel.
}
In this graph, every core resource has a label, so sorting them out by class is a good way to find the labels of only the articles.
Restricting the pattern to a particular named graph
If the triplestore has many named graphs, we can specify that some triple patterns must occure in a certain named graph, but not others. The following graph pattern only looks for the triple pattern in the graph http://vanderbilt.edu/faculty:
{
GRAPH <http://vanderbilt.edu/faculty> {
?person foaf:givenName "Jonathan".
?person foaf:familyName "Smith".
}
}
Triple patterns restricted to a certain graph can be combined with triple patters in a different graph or no specific graph. Here’s an example:
{
GRAPH <http://bioimages.vanderbilt.edu/people> {?s1 rdf:type ?class.}
GRAPH <http://vanderbilt.edu/wikidata> {?s2 rdf:type ?class.}
}
This graph pattern restricts ?class to classes that the two graphs have in common.
Restricting conditions with FILTER
There are many conditions that can be used to limit the graph pattern. FILTER sets conditions on the values that can be bound to variables. For example:
{
?person foaf:givenName ?firstName.
FILTER (?firstName != "Steve")
}
would exclude people whose first names were “Steve”. In this example:
{
?book dcterms:created ?year.
FILTER (?year < "1928")
}
?book is restricted to those created before 1928. (Note: in this example, ?year is a plain literal string. Times and dates may also be datatyped, wihch complicates the comparison.)
Here’s a filter that restricts the pattern to titles that have English language tags:
{
?book dcterms:title ?name.
FILTER (langMatches(lang(?name)),"en")
}
The langMatches() function allows the language tag to be generic “en” or a subtag like “en-US”.
Query prologues
The prologue is listed at the start of the query and is used to specify the namespace prefixes that can be used in CURIEs (URI abbreviations). Here are some of the common ones, listed in the format used by SPARQL:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX dcterms: <http://purl.org/dc/terms/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX : <http://example.org/>
This form of prolog is used in all of the types of SPARQL queries.
Any abbreviation (including the empty one :) can be used for a namespace. However, the ones listed above are conventionally used (with some variation). The empty namespace abbreviation is often used in examples to indicate that the namespace isn’t important. So it may be assigned to a namespace like http://example.org/.
SELECT SPARQL queries
The SELECT query type simply reports the values of variables that are bound in each solution to the graph pattern. Here’s the form of a SELECT query:
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT ?book
WHERE
{
?book dcterms:created ?year.
FILTER (?year < "1928")
}
For compactness, the query could also be written as:
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT ?book WHERE {
?book dcterms:created ?year.
FILTER (?year < "1928")
}
The result of a SELECT query is all of the bindings that satisfy the graph pattern, including redundant ones. Since we usually don’t care about redundance, the keyword DISTINCT can be added to include only unique bindings in the results:
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT DISTINCT ?book WHERE {
?book dcterms:created ?year.
FILTER (?year < "1928")
}
The SELECT clause can be used to return more than one bound variable.
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT DISTINCT ?author ?year WHERE {
?book dcterms:created ?year.
?book dcterms:creator ?author.
}
The query above would provide a list of authors and the years in which they created things. It would not break the results down by book. If we want the query to return all of the variables included in the graph pattern, we can use *:
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT DISTINCT * WHERE {
?book dcterms:created ?year.
?book dcterms:creator ?author.
}
Using * is a good trick to list triples:
SELECT DISTINCT * WHERE {
?subject ?predicate ?object.
}
LIMIT 10
Since there may be many results in a query like this, it’s probably safest to include a LIMIT clause to just get a small sample of the results.
Building the dataset
By default, the query is run on all of the triples in the database. If you only want to include part of the triples, you can build a dataset by specifying the graphs to be included in the query using FROM clauses. Here’s an example:
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT DISTINCT ?book
FROM <http://vanderbilt.edu/orcid>
FROM <http://vanderbilt.edu/wikidata>
FROM <http://vanderbilt.edu/doi>
WHERE {
?book dcterms:created ?year.
?book dcterms:creator ?author.
}
The dataset used in the query would consist of only the three graphs: http://vanderbilt.edu/orcid, http://vanderbilt.edu/wikidata, and http://vanderbilt.edu/doi. All other triples in the triplestore would be ignored.
FROM clauses can be used in any kind of SPARQL query.
Sample SELECT queries
The following queries can be carried out using the Linked Data Working Group’s SPARQL endpoint (https://sparql.vanderbilt.edu/). They are based on the 66 triples included in the graph that we’ve been using in the examples. It’s a named graph with the URI http://vandy (no trailing slash!). So to exclude other triples in the database, we use an appropriate FROM clause. The first example includes abbreviations for all of the namespaces included in the graph. Many will not be needed in particular queries, but it doesn’t hurt to just include them all as you hack.
List all triples in the graph
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX dcterms: <http://purl.org/dc/terms/>
PREFIX grid: <http://www.grid.ac/ontology/>
PREFIX geo: <http://www.w3.org/2003/01/geo/wgs84_pos#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX madsrdf: <http://www.loc.gov/mads/rdf/v1#>
PREFIX bibo: <http://purl.org/ontology/bibo/>
SELECT DISTINCT *
FROM <http://vandy>
WHERE {
?subject ?predicate ?oboject.
}
List URIs and names of all articles (query by class)
SELECT DISTINCT ?article ?title
FROM <http://vandy>
WHERE {
?article a foaf:Document.
?article rdfs:label ?title.
}
List names of articles published before 2015 (using a FILTER)
SELECT DISTINCT ?title ?date
FROM <http://vandy>
WHERE {
?article a foaf:Document.
?article rdfs:label ?title.
?article dcterms:created ?date.
FILTER (?year < "2014")
}
List names of articles created by people whose family name is “Hillyer” (traversing one link in the graph)
SELECT DISTINCT ?title
FROM <http://vandy>
WHERE {
?article a foaf:Document.
?article rdfs:label ?title.
?article dcterms:creator ?person.
?person foaf:familyName "Hillyer"
}
List the starting page numbers of articles written by people affiliated with institutions located in cities named “Nashville” (traversing two links in the graph)
SELECT DISTINCT ?startingPage
FROM <http://vandy>
WHERE {
?university grid:cityName "Nashville".
?person madsrdf:hasAffiliation ?university.
?article dcterms:creator ?person.
?article bibo:pageStart ?startingPage.
}
CONSTRUCT SPARQL queries
The CONSTRUCT SPARQL query form is similar to the SELECT form because both use graph patterns to bind to variables parts of triples that fulfill the graph pattern. In the SELECT form, those variables (or things related to them, like counts) are simply reported. However, in the CONSTRUCT query form the bound variables are used to actually create new triples based on patterns specified in the CONSTRUCT clause.
A CONSTRUCT query has the general form
CONSTRUCT {
graph to be constructed
}
WHERE {
graph pattern to be satisfied
}
The CONSTRUCT query can have PREFIX definitions in a prolog and can be restricted to particular graphs using FROM statements just as in the case of SELECT queries.
Here is an example that can be tested at the Vanderbilt SPARQL endpoint:
PREFIX dcterms: <http://purl.org/dc/terms/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT {
?book foaf:maker ?author.
}
FROM <http://vandy>
WHERE {
?book dcterms:creator ?author.
}
In this example, we find sets of books that are connected to authors by the dcterms:creator property and create a new graph that contains triples where those authors are connected to their books by a different property: foaf:maker. Each binding of an author and a book is used to construct one triple connecting that author and book using the new property.
In this case, DCMI and the creators of FOAF agreed that the two terms, dcterms:creator and foaf:maker are equivalent. So in theory, a sufficiently smart computer could figure out that a triple containing one of those properties entails another triple using the other property. But a generic triplestore and SPARQL endpoint doesn’t automatically do that kind of reasoning, so by using SPARQL CONSTRUCT, we can “materialize” those entailed triples and manually insert them back into the dataset by loading the result of the CONSTRUCT query back into the triplestore.
A very similar use case involves FOAF and schema.org terms. Here is a CONSTRUCT query that converts FOAF terms to a schema.org term:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX schema: <https://schema.org/>
CONSTRUCT {
?thing schema:name ?name.
}
WHERE {
?thing foaf:firstName ?givenName.
?thing foaf:familyName ?surname.
BIND( CONCAT(?givenName, " ", ?surname) as ?name)
}
Notice the trick used to create an entire schema.org name from separate given- and surnames. The graph pattern as it is shown requires that a thing have both a first and last name in order for the combined name to be constructed.
Getting a triple dump from an endpoint
SPARQL CONSTRUCT can be used to pull all of a particular category of triples from a triplestore based on the restrictions given in the graph pattern or the FROM statement. Here’s an example that downloads one particular graph from a triplestore (this one can also be tested at the Vanderbilt SPARQL endpoint):
CONSTRUCT {
?subject ?predicate ?object.
}
FROM <http://vandy>
WHERE {
?subject ?predicate ?object.
}
Notice that the graph pattern places no restriction on the triples – they are only restricted by the FROM clause, which says that the triples have to be from the http://vandy graph.
Here is a construct query that retrieves all of the statements about “Shaul Kelner” and can be performed at the Vanderbilt endpoint:
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
CONSTRUCT {
?person ?predicate ?object.
}
WHERE {
?person rdfs:label "Shaul Kelner".
?person ?predicate ?object.
}
In this example, the values of the ?person variable are constrained to be people labeled as “Shaul Kelner”. The other two variables can have any value. It is not restricted to the http://vandy graph, and picks up a lot more triples that came from other graphs in the triplestore.
Refactoring data from Wikidata
Although the Wikidata data model can be expressed as RDF, it has some significant differences from standard Linked Data practices. In particular, all entities are “items” and don’t have rdf:type assignments. Nearly all properties are ideosyncratic to Wikidata, so with the notable exception of rdfs:label, virtually none of the “standard” Linked Data properties (Dublin Core, FOAF, schema.org, etc.) are used. (Note: the Wikidata data model is essentially the same as the data model used by the generic Wikibase platform.)
Another challenge is that since Wikidata is by design very multilingual, acquiring every label will often result in more labels than are needed. So filtering labels for particular languages can be helpful.
If we want to harvest data from Wikidata but express it in more standard terms, we can use CONSTRUCT queries. Here is an example that can be run at the Wikidata query service:
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX dcterms: <http://purl.org/dc/terms/>
PREFIX schema: <https://schema.org/>
CONSTRUCT {
?president a foaf:Person.
?president wdt:P39 wd:Q11696.
?president rdfs:label ?nameEn.
?president schema:name ?name.
?president foaf:familyName ?lastName.
?president foaf:firstName ?firstName.
?president dcterms:created ?birthDate.
}
WHERE {
?president wdt:P39 wd:Q11696. #position held = President of the United States of America
?president wdt:P31 wd:Q5. #restricts to actual humans vs. fictional humans
?president wdt:P569 ?birthDate.
# find English labels (the person's name) and drop the language tag
?president rdfs:label ?nameTagged.
FILTER (langMatches(lang(?nameTagged),"en"))
BIND (str(?nameTagged) AS ?name)
# create a language-tagged value to use for rdfs:label
BIND (STRLANG(?name,"en") AS ?nameEn)
# pull out only the last names
?president wdt:P734 ?surname.
?surname rdfs:label ?lastNameTagged.
FILTER (langMatches(lang(?lastNameTagged),"en"))
BIND (str(?lastNameTagged) AS ?lastName)
# pull out only the first names
?president wdt:P735 ?givenname.
?givenname rdfs:label ?firstNameTagged.
FILTER (langMatches(lang(?firstNameTagged),"en"))
BIND (str(?firstNameTagged) AS ?firstName)
}
Notes:
- We assert
rdf:typeoffoaf:Personto all of the presidents due the screening we did by requiring them to be presidents. FOAF doesn’t actually require the to be real people. - There isn’t really a well-known property for “position held” or controlled vocabulary that includes “presidents of the United States”, so that property and value were just passed through to the new graph as-is.
- In Wikidata, given names and surnames are items, not string labels (literals). So to acquire the name strings themselves, we need to find the labels of the name items.
- There aren’t really rules for how terms can be used, so I chose to use
dcterms:createdfor the birth dates. That’s kind of a non-standard use for a very well-known term. It also has a different intended meaning that its somewhat ambiguous use in thehttp://vandygraph where the value given was the date the record was created (see the value for Shaul Kelner).
You can look at the resulting data (retrieved on 2019-03-14) as RDF/XML or as RDF/Turtle.
This example illustrates how the work done by the many people who support Wikidata can be leveraged to create a Linked Data dataset using pretty much any vocabulary we choose.
Retrieving SPARQL query data using HTTP
The queries that we tested above are good training exercises, but how can we use SPARQL as a tool to help us actually acquire data for projects? In addition to being a query language, SPARQL is also a protocol that works with HTTP to make it possible to submit queries and retrieve results using client software that can operate without human intervention. The following sections will provide a few examples of how to do that in real life.
Acquiring triples from an endpoint using POST
The Wikidata query examples above can be pasted directly into the Wikidata Query Service query box. The resulting triples will show up in tabular form in the box at the bottom of the page.
This method is fine for testing queries. But one major deficiency of those results is that language tagging and xsd: datatyping are not shown in the results. Also, the results can be downloaded to a file, but the downloaded formats are not valid serializations of RDF triples.
To get clean RDF triples, we need to use a client that can carry out HTTP calls and return the results in a usable form. Postman is a relatively easy to use graphical application that can be used for this purpose.
Most SPARQL queries can be made using either HTTP GET or POST. (There is a limit to the size of GET queries, but it is rather large.) In the case of Vanderbilt’s SPARQL endpoint, POST queries cannot be made without authentication, so GET is the only option there. The Wikidata endpoint allows either without authentication. The disadvantage of GET queries is that they must be URL-encoded before sending, which adds an extra layer of complexity. So for this example, we’ll use POST to the Wikidata Query Service endpoint.
Here are the details required:
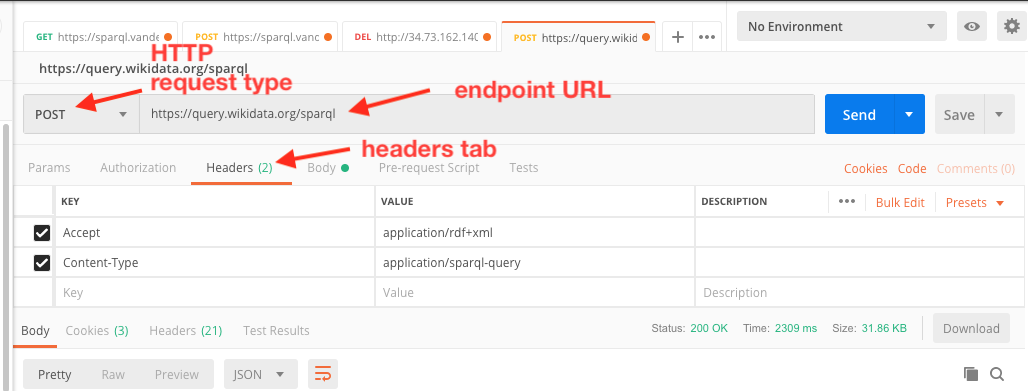
1. The query endpoint URL is https://query.wikidata.org/sparql
2. The HTTP request type should be set to POST.
3. On the Headers tab, set a key of Content-Type and a value of that key of application/sparql-query. This is required and the query will NOT work if this header isn’t sent!
4. On the Headers tab, set a key of Accept and a value for that key of application/rdf+xml to get RDF/XML. To get RDF/Turtle (if supported by the endpoint), use a value of text/turtle. To get JSON-LD, use a value of application/ld+json.
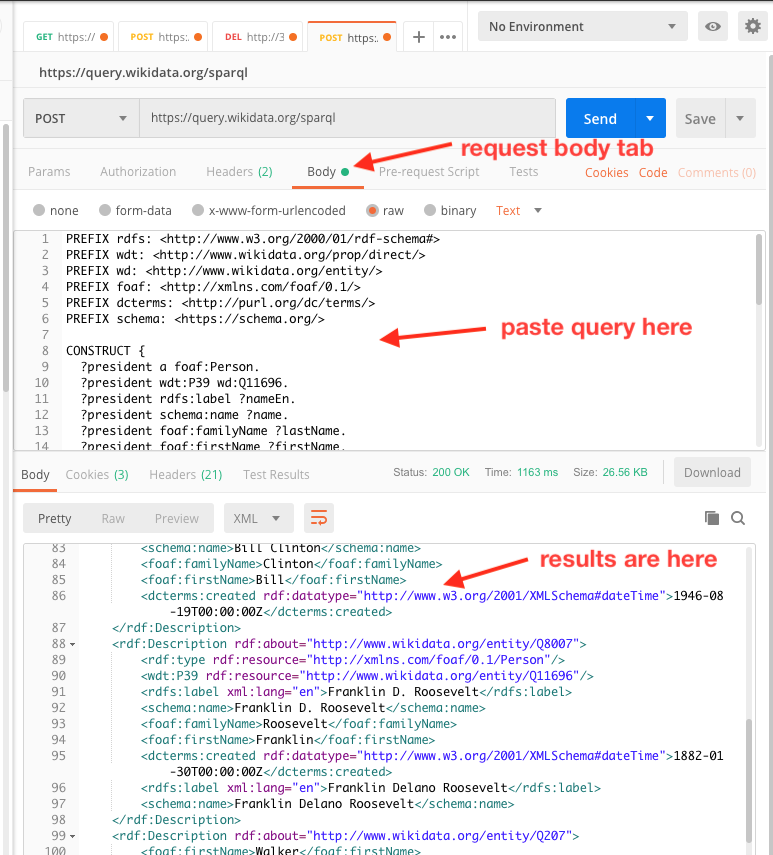
5. On the Body tab, click the raw radio button. Then in the box below, paste the query.
6. Click the Send button.
In the box at the botton, you should see correctly serialized RDF/XML. Notice that here the datatyping for the dateTime is correct and that the English language label was applied to the rdfs:label value, but not the various name values as specified in the CONSTRUCT query.
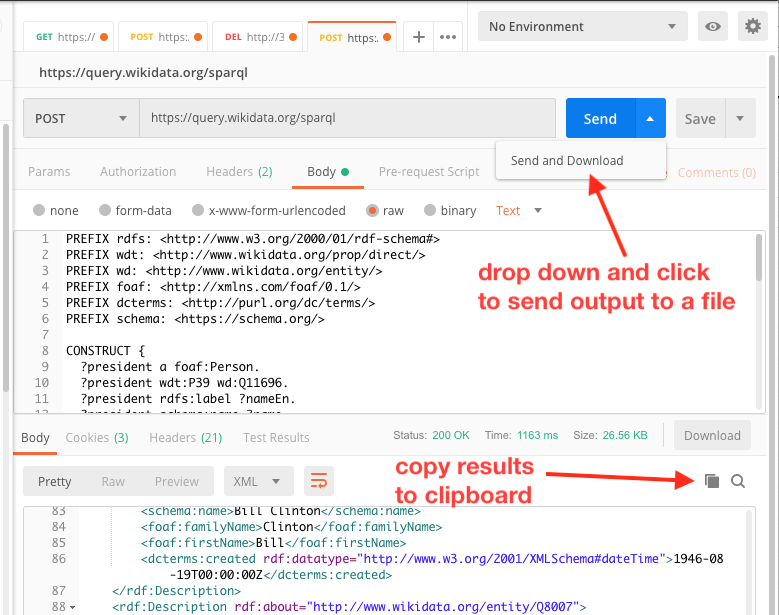
For query with a few results, you can just click on the little copy icon (to the left of the magnifing lens icon at the top of the results pane) and paste into a text document, then save. For larger queries, drop down the Send button and select Send and Download. After the results have been received, you’ll be propted for a save location and filename.
The resulting RDF/XML file can be loaded into a SPARQL endpoint if desired.
Acquiring triples from an endpoint using GET
An HTTP GET request is somewhat simpler than a POST request, since there is no text body to be sent to the server. Instead, the query is sent as a part of a query string appended to the URL itself. The SPARQL protocol for GET is more relaxed than POST about the headers and will generally default to RDF/XML if no Accept header is sent. The downside is that the query itself has to be URL encoded to make all of the non-alphanumeric characters “safe” to be included in a URL. Here are the steps to do a GET request using Postman:
1. The query endpoint URL is https://query.wikidata.org/sparql
2. The HTTP request type should be set to GET.
3. Click on the Params tab, and set a key of query.
4. Go to a URL encoding website. I usually use this one.
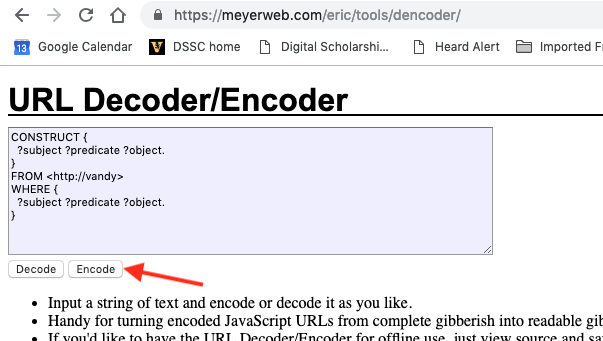
Paste the query into the box, then click the Encode button.
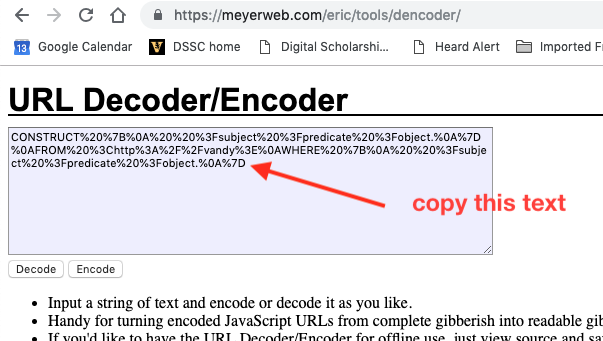
Copy the encoded text and paste it into the Value box for the query key. You’ll see the entire icky URL in the URL box above.
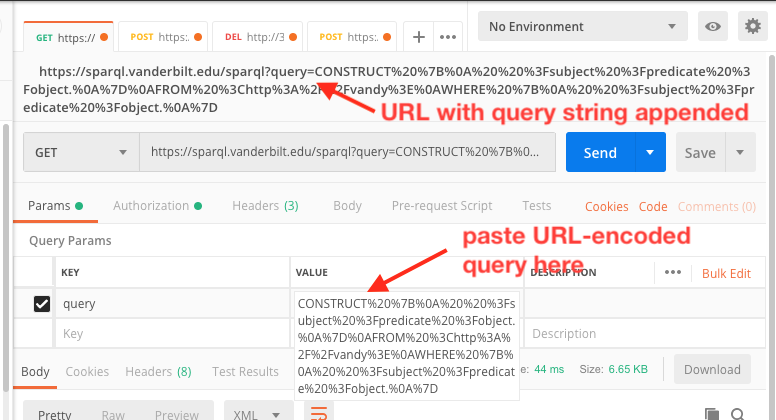
5. If you don’t care about the serialization of the results, just click the Send button. Otherwise, set an Accept header as described in step 4 above.
6. You can also download the results as explained in the POST example.
Harvesting data from Wikidata programatically
In the examples above, we retrieved the results of CONSTRUCT queries “manually” using Postman in order to have discrete files of serialized RDF data to load into a triplestore. Because most programming languages have mechanisms for making HTTP calls directly from a script, data from either a SELECT or CONSTRUCT query can be retrieved directly from a SPARQL endpoint by the script and used as a data source.
You can view an example of a Python script that retrieves data from Wikidata about cartoon caracters and a similar Python script with a graphical interface. If you have Python 3 installed on your computer, you can run either of these scripts to see what they do. The only library that needs to be installed using PIP is the Requests library (if you don’t already have it).
The heart of the script is this function (lines 25 through 42 of the first script:
def getWikidata(characterId):
endpointUrl = 'https://query.wikidata.org/sparql'
query = '''select distinct ?property ?value
where {
<''' + characterId + '''> ?propertyUri ?valueUri.
?valueUri <http://www.w3.org/2000/01/rdf-schema#label> ?value.
?genProp <http://wikiba.se/ontology#directClaim> ?propertyUri.
?genProp <http://www.w3.org/2000/01/rdf-schema#label> ?property.
FILTER(substr(str(?propertyUri),1,36)="http://www.wikidata.org/prop/direct/")
FILTER(LANG(?property) = "en")
FILTER(LANG(?value) = "en")
}'''
# The endpoint defaults to returning XML, so the Accept: header is required
r = requests.get(endpointUrl, params={'query' : query}, headers={'Accept' : 'application/sparql-results+json'})
data = r.json()
statements = data['results']['bindings']
return statements
The value of the endpointUrl variable is set to the Wikidata query service endpoint URL. The value of the query string variable is hard-coded with the value of the Wikidata identifier (characterId) substituted in the appropriate place. The line
r = requests.get(endpointUrl, params={'query' : query}, headers={'Accept' : 'application/sparql-results+json'})
is where the HTTP request is made – you can see where the query parameter and Accept header is inserted, just as we did with Postman. In this case, the requested content type to get JSON is application/sparql-results+json. The resulting data come back as a JSON object that looks like this:
{
"head": {
"vars": [
"property",
"value"
]
},
"results": {
"bindings": [
{
"value": {
"xml:lang": "en",
"type": "literal",
"value": "United States of America"
},
"property": {
"xml:lang": "en",
"type": "literal",
"value": "country of citizenship"
}
},
{
"value": {
"xml:lang": "en",
"type": "literal",
"value": "Superman"
},
"property": {
"xml:lang": "en",
"type": "literal",
"value": "present in work"
}
}
]
}
}
with many results omitted. The line
statements = data['results']['bindings']
pulls out the array of results and returns it so that the program can do what it wants with the data.
Here’s what the script with a graphical interface looks like when it runs:
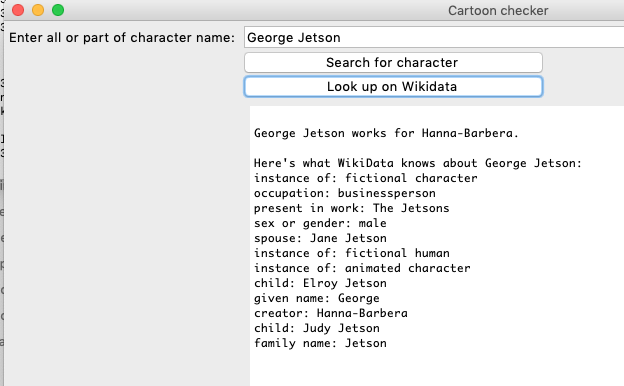
If you don’t count the lines required to assign the SPARQL query to the query variable, only a very few lines of code are required to access the vast universe of data that is available in Wikidata. Of course, knowing how to construct the SPARQL SELECT query requires understanding the Wikidata data model, which is discussed in the following lesson.
Lesson on the Wikibase data model
Revised 2019-03-18

Questions? Contact us
License: CC BY 4.0.
Credit: "Vanderbilt Libraries Digital Lab - www.library.vanderbilt.edu"